Lesson 1.13: Decision Tree Learning
A tree-like model that illustrates series of events leading to certain decisions. Each node represents a test on an attribute and each branch is an outcome of that test.
- We use labeled data to obtain a suitable decision tree for future predictions.
- We want a decision tree that works well on unseen data, while asking as few questions as possible.
- Basic step: choose an attribute and, based on its values, split the data into smaller sets.
- Recursively repeat this step until we can surely decide the label.
Pseudocode for making a decision tree

Decision Tree Learning Process
- Input: Labeled training data (features + target class)
- Goal: Build a tree that:
- Generalizes well to unseen data
- Makes decisions with minimal questions (shallow depth)
- Recursive Splitting:
- Select best attribute at each node
- Split data into subsets based on attribute values
- Repeat until stopping criteria met
When to Create a Leaf Node?
A node becomes a leaf when:
- Pure node: All samples belong to one class (e.g., 100% "Yes" or 100% "No")
- No remaining features to split on
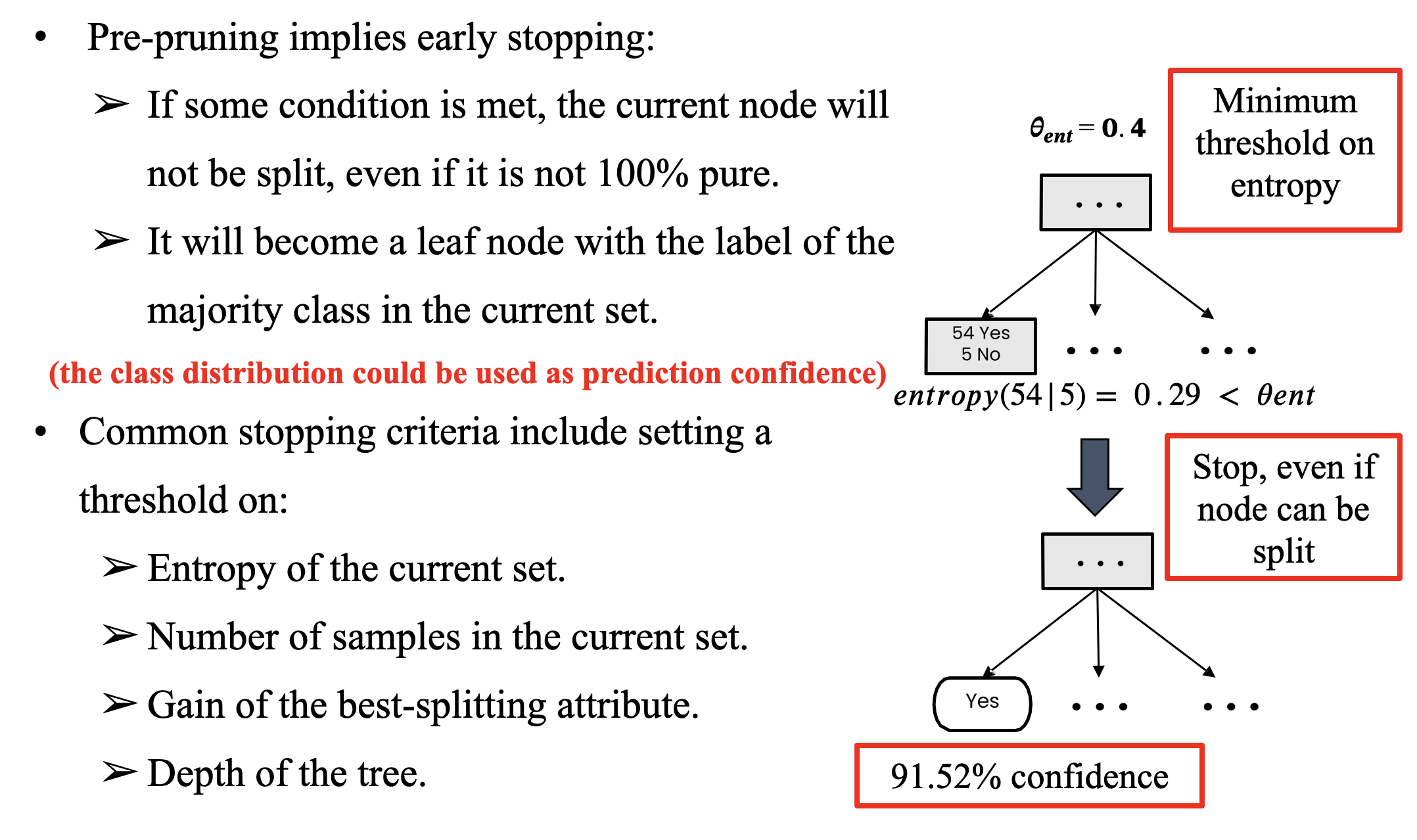
- Pre-pruning: Early stopping if split doesn't improve purity significantly
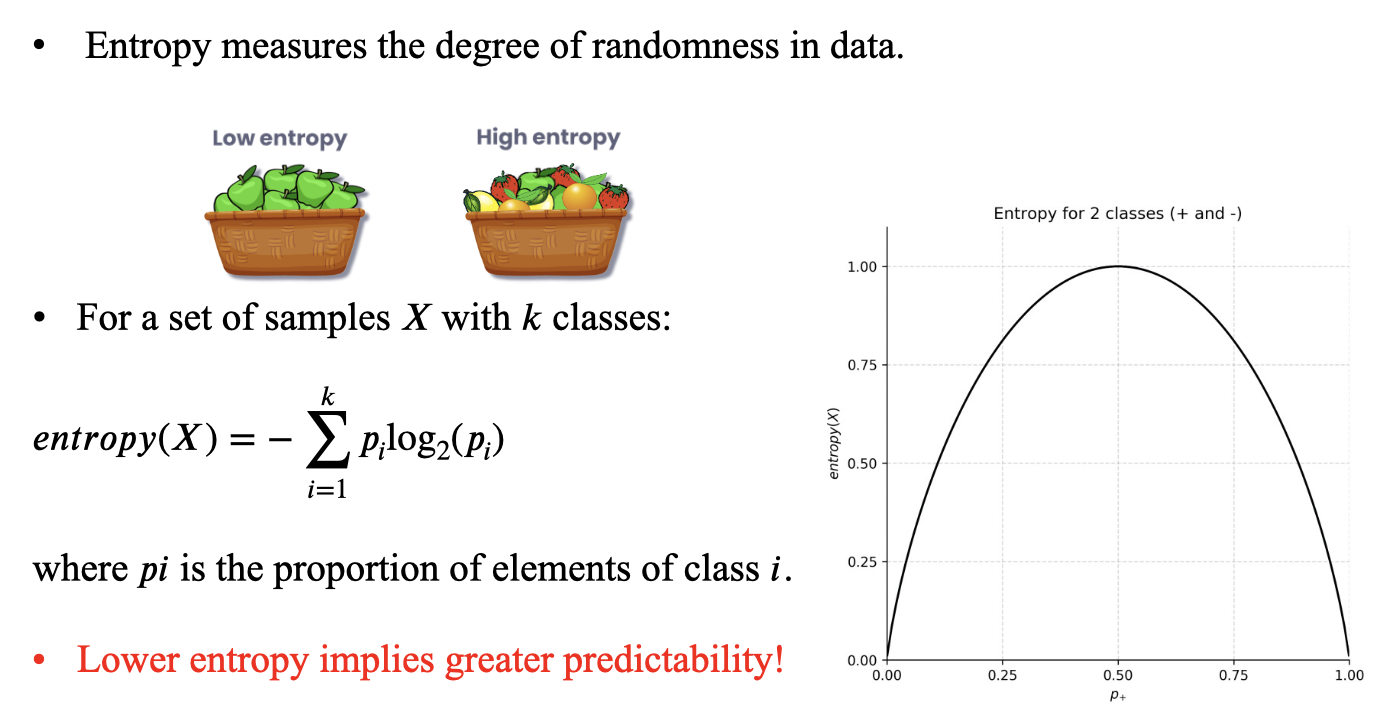
Entropy
Entropy measures the uncertainty or randomness in a dataset. It quantifies how "mixed" the class labels are in a given subset of data.
Information Gain
Information Gain (IG) measures how much an attribute reduces uncertainty (entropy) about the class when splitting a dataset. It helps select the best attribute for decision tree nodes.
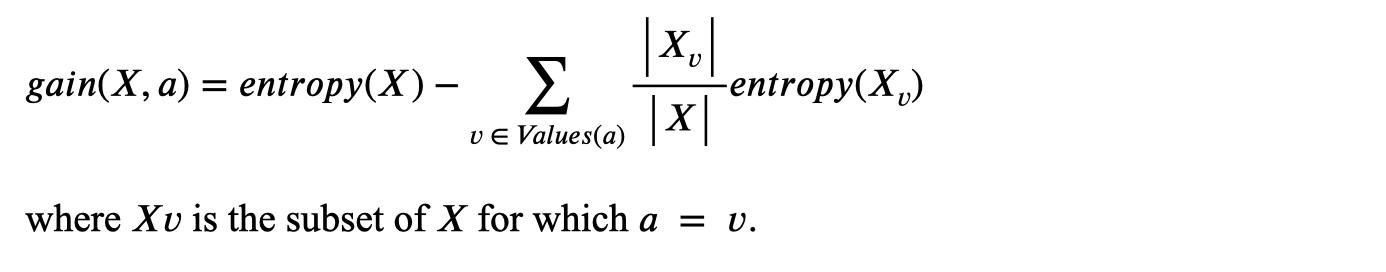
- For attribute A and dataset S:
- Where:
- : Entropy of the original set
- : Subset of where attribute has value
- : Proportion of samples in subset
- Goal: Maximize IG → Choose the attribute that most reduces entropy after splitting.
Step-by-Step Example
Dataset: Weather Conditions → Play Tennis?
| Outlook | Humidity | Wind | Play Tennis? |
|---|---|---|---|
| Sunny | High | Weak | No |
| Sunny | High | Strong | No |
| Overcast | High | Weak | Yes |
| Rainy | High | Weak | Yes |
| Rainy | Normal | Weak | Yes |
| Rainy | Normal | Strong | No |
| Overcast | Normal | Strong | Yes |
| Sunny | High | Weak | No |
Target: Predict "Play Tennis?" (Yes/No)
Information Gain Calculation in Decision Trees
Step 1: Calculate Original Entropy
Dataset Statistics:
- Total samples: 8
- Class distribution:
- "Yes" (Play Tennis): 5
- "No" (Don't Play): 3
Entropy Formula:
Calculation:
Step 2: Calculate Entropy After Splitting on "Outlook"
Attribute Values:
- Sunny (3 samples)
- Overcast (2 samples)
- Rainy (3 samples)
a) Sunny Subset ()
- Samples: 3 "No", 0 "Yes"
b) Overcast Subset ()
- Samples: 2 "Yes", 0 "No"
c) Rainy Subset ()
- Samples: 2 "Yes", 1 "No"
Weighted Average Entropy:
Step 3: Compute Information Gain for "Outlook"
Information Gain Formula:
Calculation:
Comparison with Other Attributes
| Attribute | Information Gain (bits) |
|---|---|
| Outlook | 0.610 |
| Humidity | 0.347 |
| Wind | 0.003 |
Key Takeaways
- Higher IG means better attribute for splitting
- "Outlook" provides the most information about the target variable
- The calculation follows:
- Compute original entropy
- Calculate weighted entropy after split
- Subtract to get information gain


Pruning

Handling Numerical Attributes




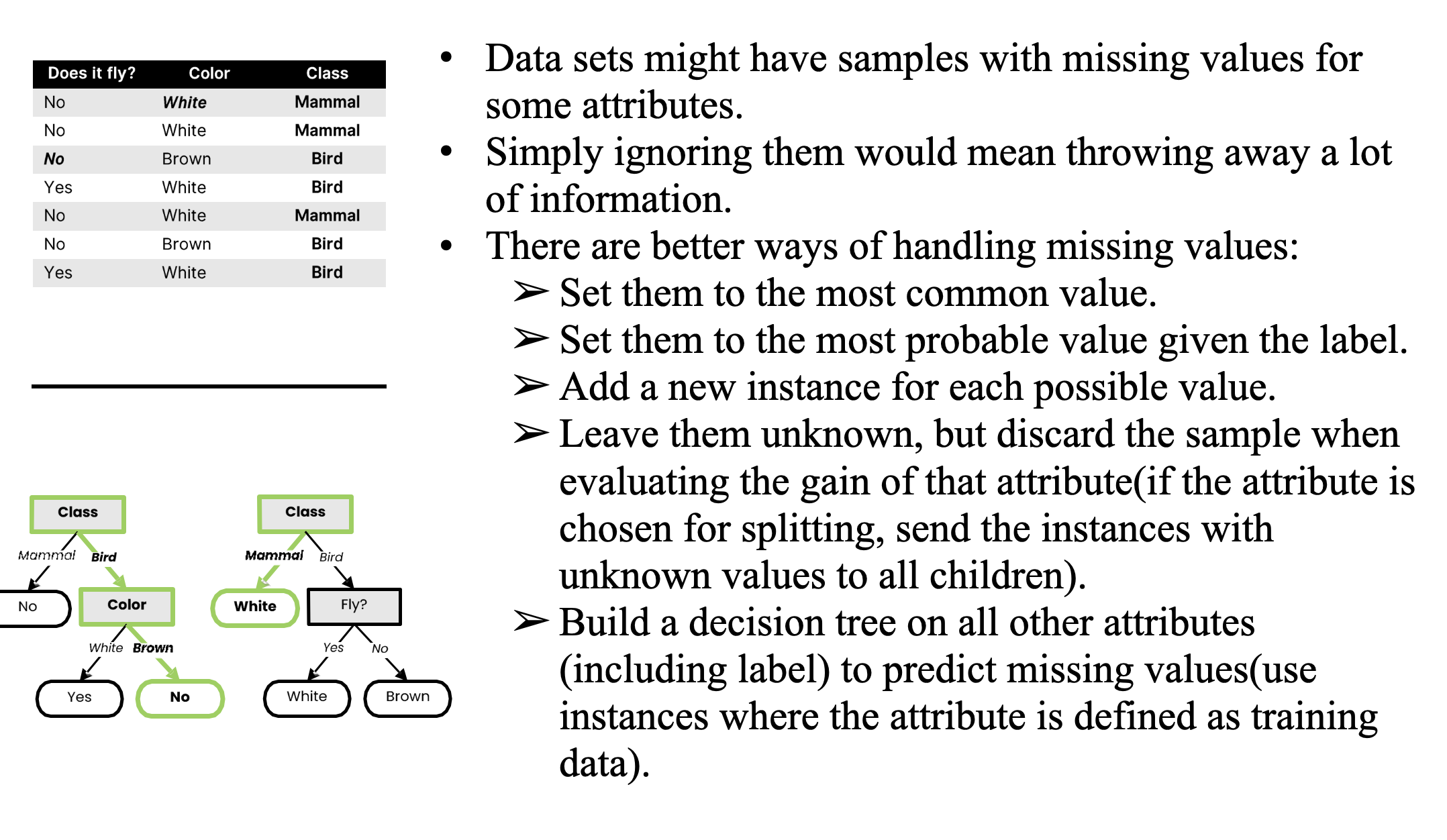
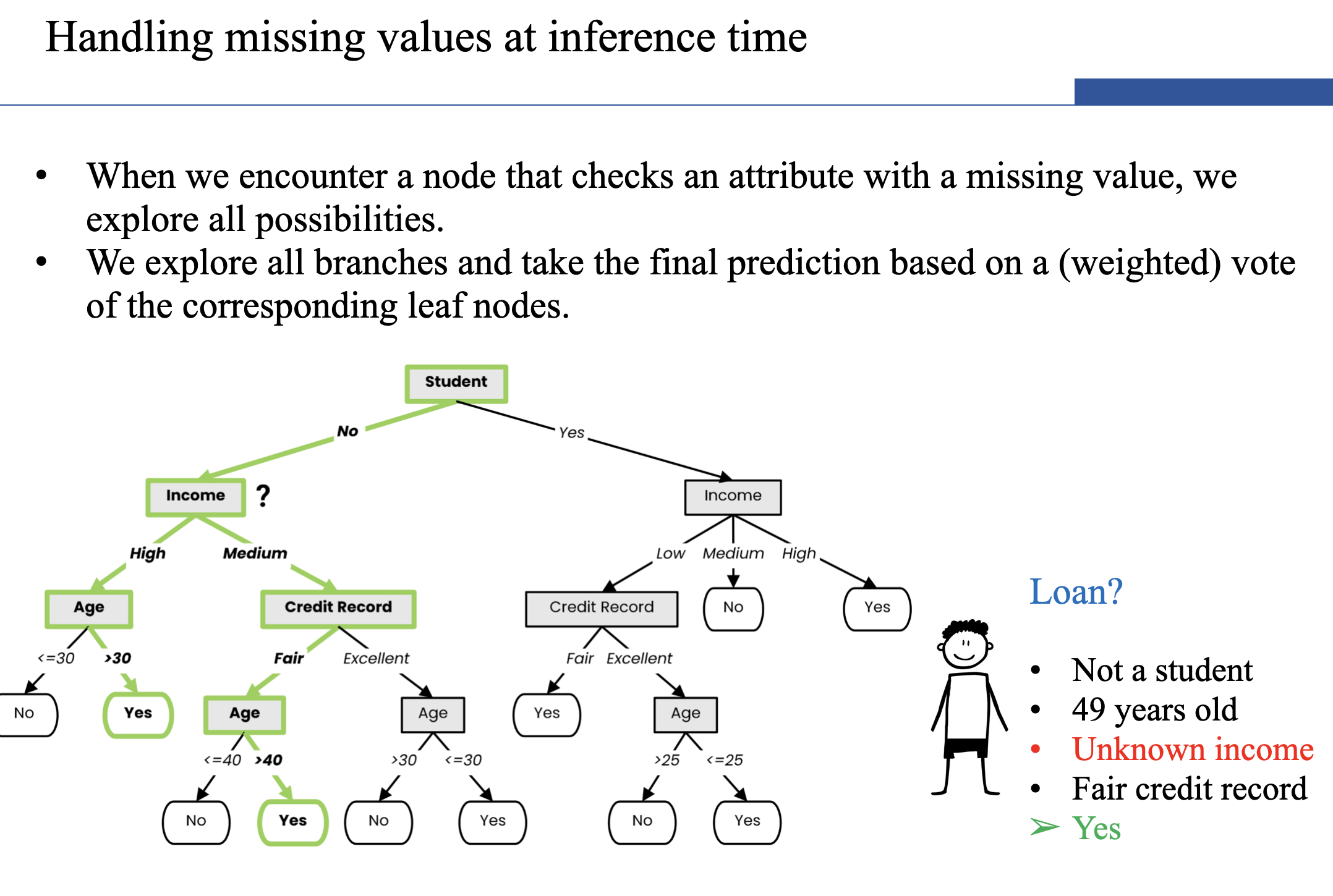
Handling Missing Attributes


Random Forests (Ensemble Learning With Decision Trees)
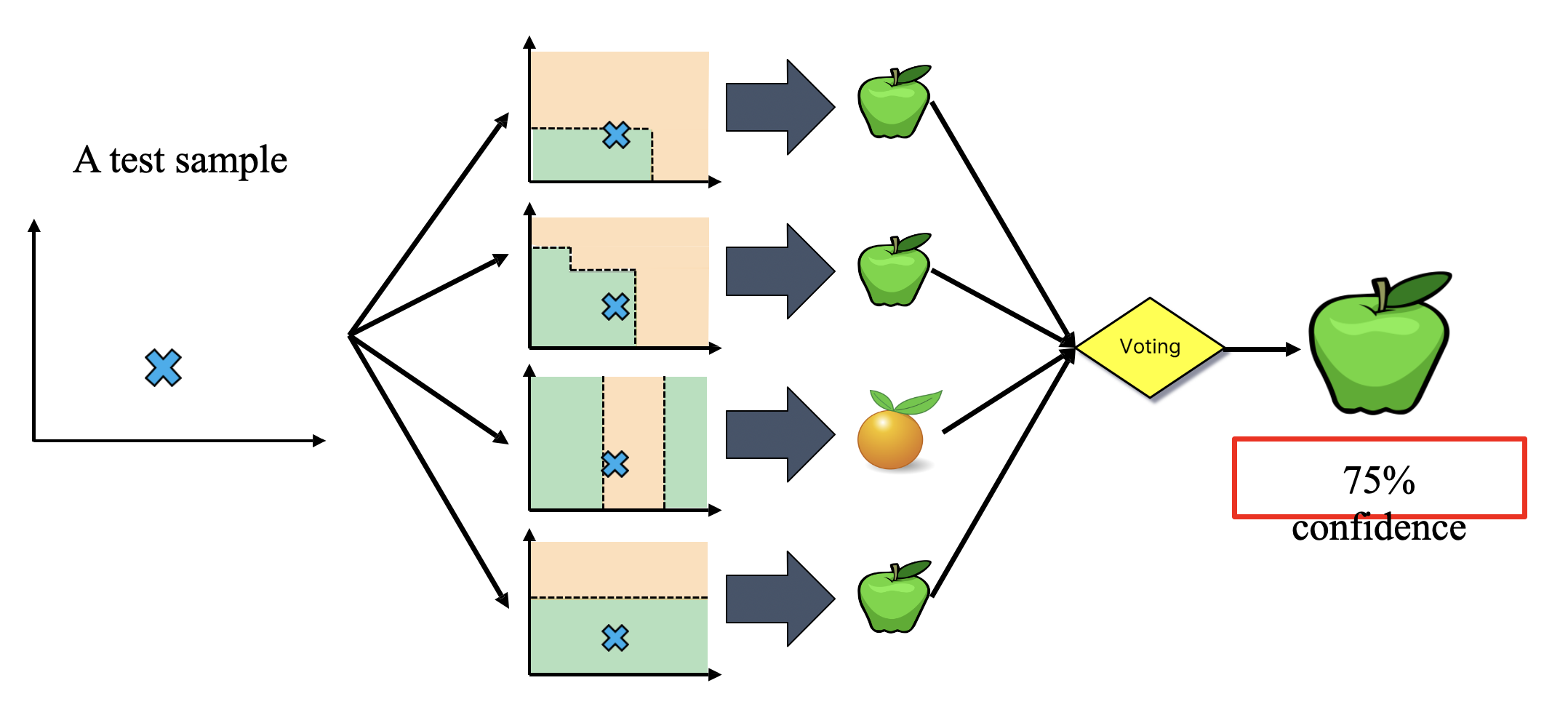
- Instead of building a single decision tree and use it to make predictions, build many slightly different trees and combine their predictions.
- We have a single data set, so how do we obtain slightly different trees?
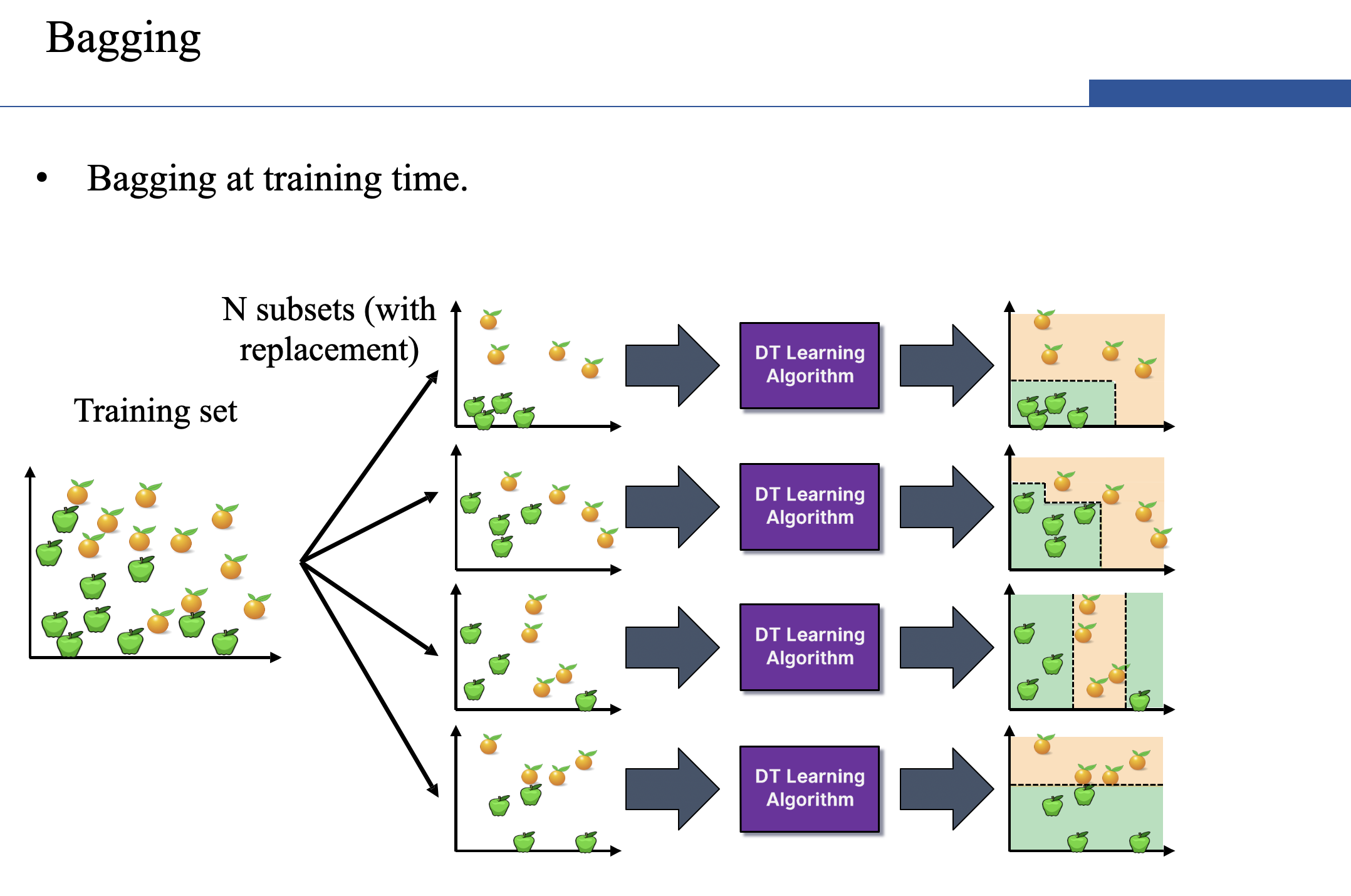
- Bagging (Bootstrap Aggregating):
- Take random subsets of data from the training set to create N smaller data sets.
- Fit a decision tree on each subset.
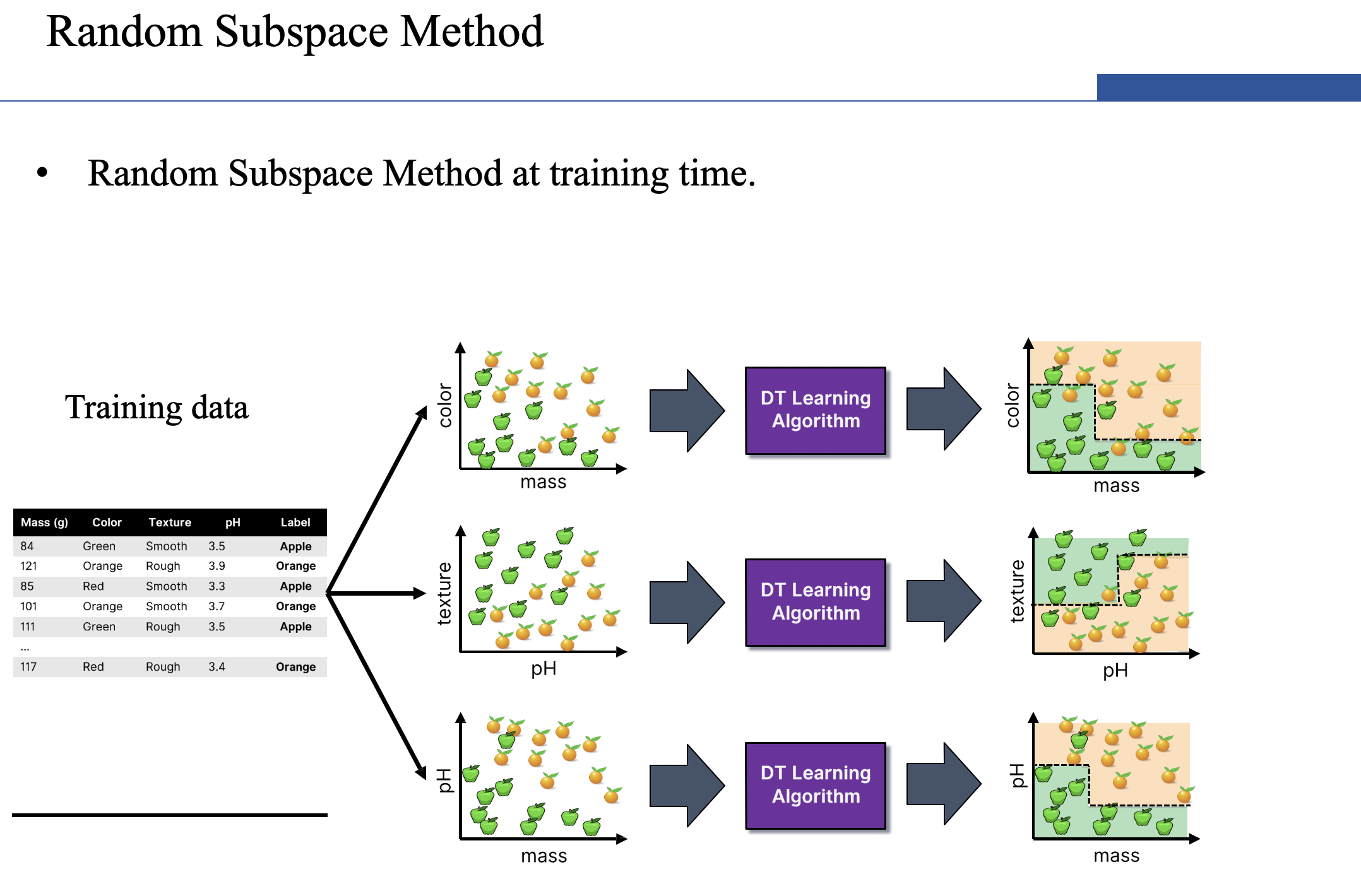
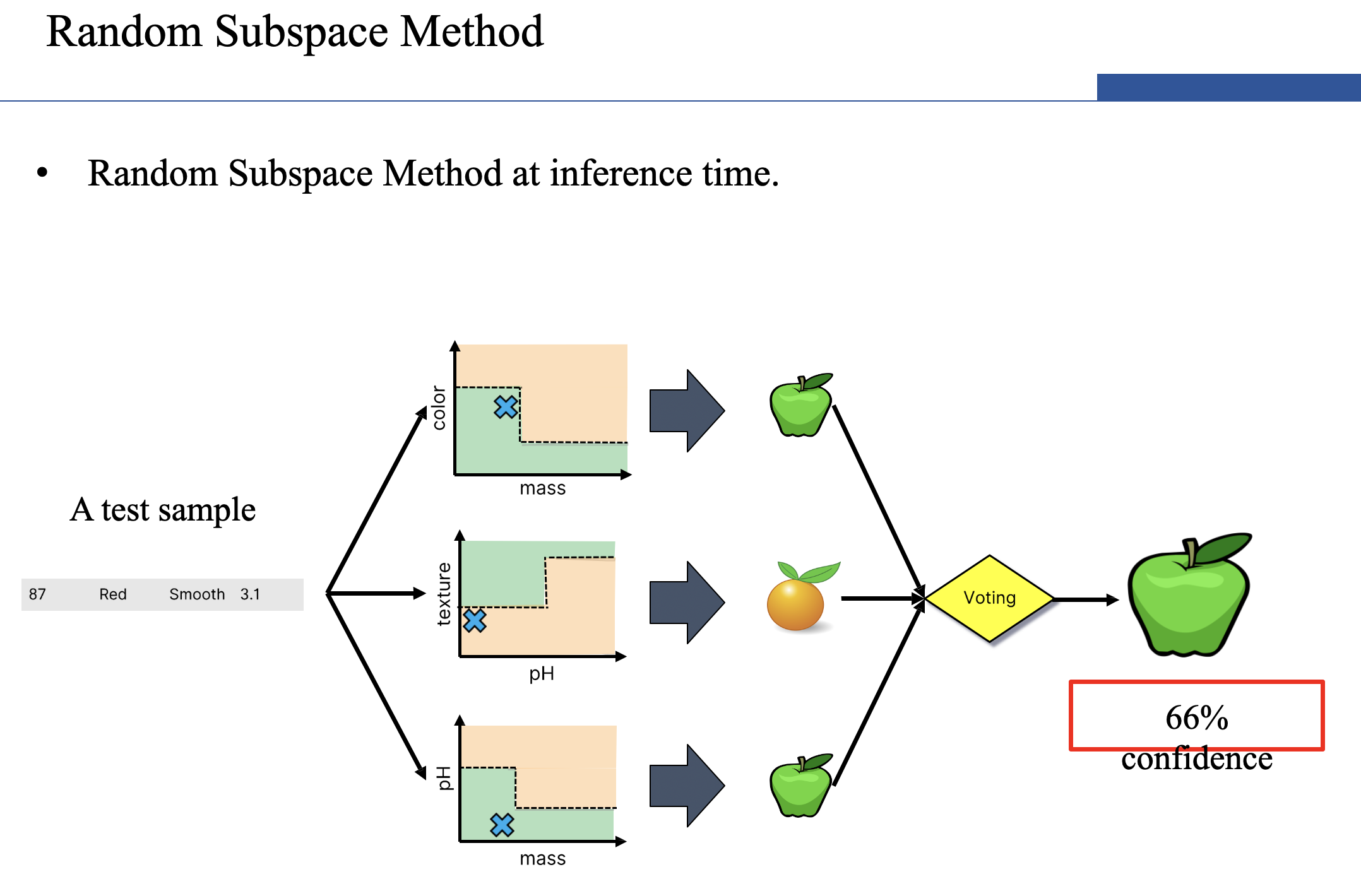
- Random Subspace Method (also known as Feature Bagging):
- Fit N different decision trees by constraining each one to operate on a random subset of features.
- Bagging (Bootstrap Aggregating):
Ensemble Learning
- Ensemble Learning:
- Method that combines multiple learning algorithms to obtain performance improvements over its components.
- Random Forests are one of the most common examples of ensemble learning.
- Other commonly-used ensemble methods:
- Bagging: multiple models on random subsets of data samples.
- Random Subspace Method: multiple models on random subsets of features.
- Boosting: train models iteratively, while making the current model focus on the mistakes of the previous ones by increasing the weight of misclassified samples.
Random Forests are an ensemble learning method that employ decision tree learning to build multiple trees through bagging and random subspace method. They rectify the overfitting problem of decision trees!