Lesson 2.1: Convolution Neural Network
What is a CNN?
A Convolutional Neural Network (CNN) is a specialized type of artificial neural network designed for processing structured grid data like images. CNNs are particularly effective for computer vision tasks because they automatically and adaptively learn spatial hierarchies of features through backpropagation.
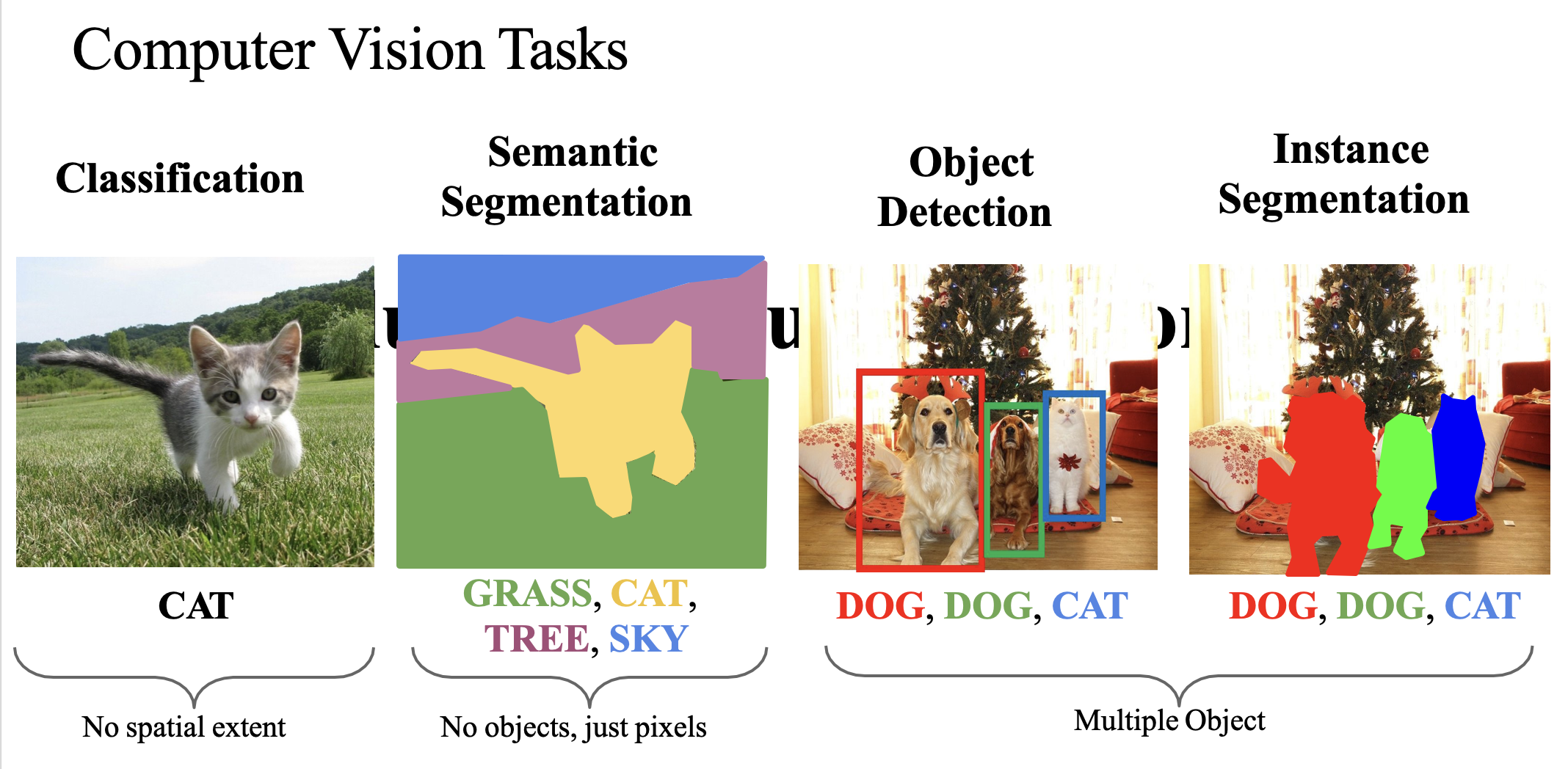
Why CNNs Over Traditional Neural Networks?
Traditional neural networks face several challenges when processing images:
-
Reduce the Number of Input Nodes
- In a traditional neural network, each pixel in an input image would be connected to each neuron in the first hidden layer. For a small 6×6 grayscale image, this means 36 input nodes. For a typical 256×256 RGB image, this would be 256×256×3 = 196,608 input nodes! This leads to:
- Computational inefficiency - too many parameters to learn
- Memory constraints - storing all these weights requires significant memory
- Overfitting - with so many parameters, the model may memorize training data rather than learn general features CNNs solve this by using local connectivity - each neuron in a convolutional layer is connected only to a small region of the input (called the receptive field), dramatically reducing the number of parameters.
- In a traditional neural network, each pixel in an input image would be connected to each neuron in the first hidden layer. For a small 6×6 grayscale image, this means 36 input nodes. For a typical 256×256 RGB image, this would be 256×256×3 = 196,608 input nodes! This leads to:
-
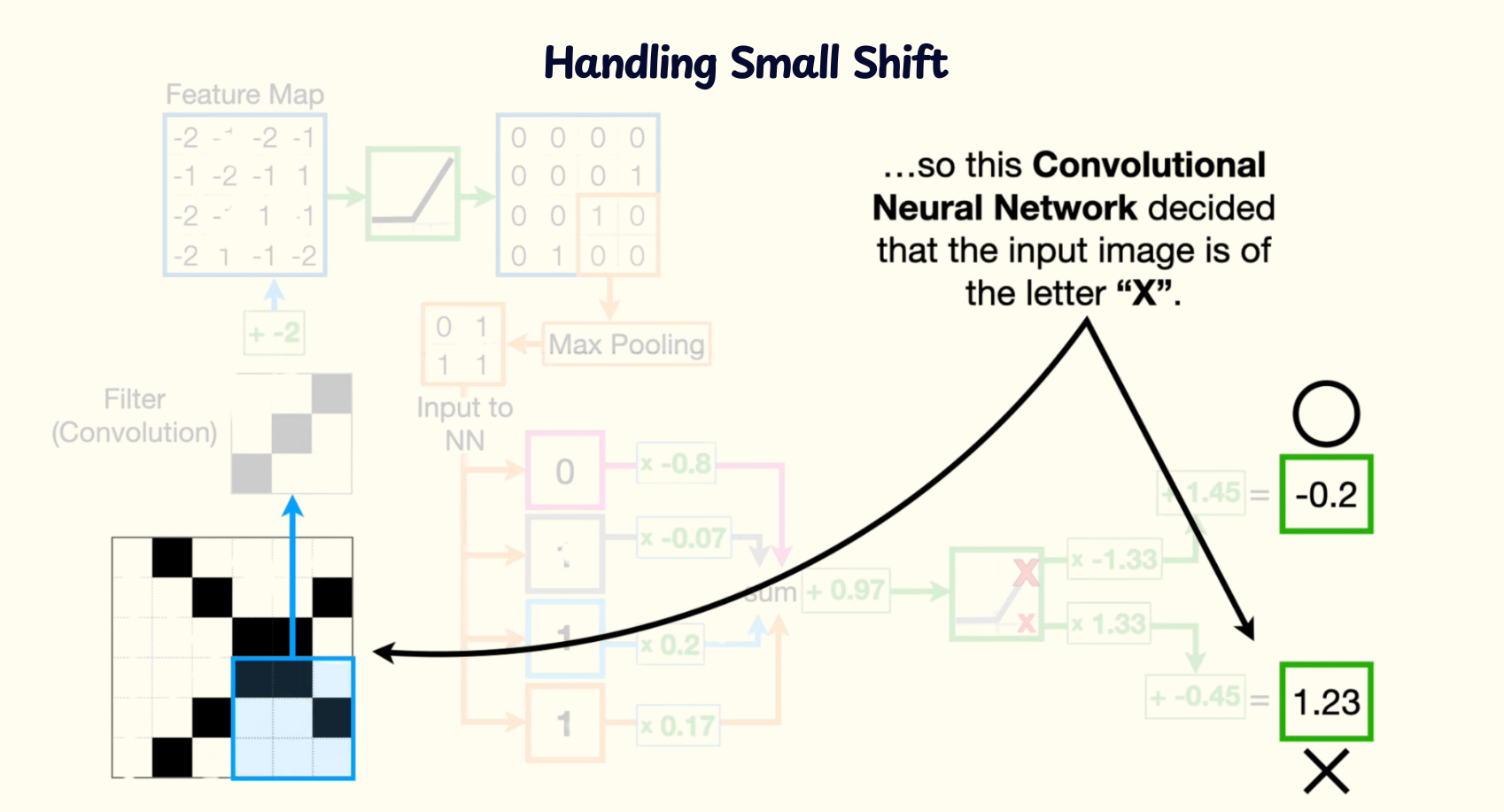
Tolerate Small Shifts in Pixel Locations
- In traditional NNs, if an object in an image shifts slightly, all the pixel values go to different input nodes, making the network see it as a completely different input. CNNs are:
- Translation invariant - the same filter is applied across the entire image, so learned features are detected regardless of their position
- Robust to small transformations - max pooling provides some invariance to small translations
- In traditional NNs, if an object in an image shifts slightly, all the pixel values go to different input nodes, making the network see it as a completely different input. CNNs are:
-
Take Advantage of Spatial Correlation
- In images, nearby pixels are highly correlated. Traditional NNs ignore this spatial structure by flattening the image into a 1D vector. CNNs preserve and exploit this structure by:
- Local connectivity - focusing on small regions at a time
- Parameter sharing - using the same weights (filters) across the entire image
- Hierarchical learning - building complex features from simple ones
- In images, nearby pixels are highly correlated. Traditional NNs ignore this spatial structure by flattening the image into a 1D vector. CNNs preserve and exploit this structure by:
| Aspect | Traditional Neural Networks | Convolutional Neural Networks (CNNs) |
|---|---|---|
| Architecture | Fully connected layers; dense connectivity between neurons. | Convolutional + pooling layers + fully connected layers; designed for grid-like data (e.g., images). |
| Local Connectivity | Global connectivity: Each neuron connected to all neurons in the previous layer. | Local connectivity: Neurons in a convolutional layer connected to a small input region (receptive field). |
| Weight Sharing | Unique weights per neuron; no parameter sharing. | Shared weights via filters/kernels across input regions; reduces parameters. |
| Pooling Layers | No pooling; rely on fully connected layers for dimensionality reduction. | Include pooling (e.g., max pooling) to downsample feature maps and retain key information. |
| Applications | Structured data (e.g., tabular data) with simple, well-defined feature relationships | Image/video processing; tasks requiring spatial hierarchies and local pattern recognition |
| Parameter Efficiency | High parameter count; prone to overfitting and computational inefficiency for high-dimensional data. | Parameter-efficient due to weight sharing and local connectivity; scalable for large datasets. |
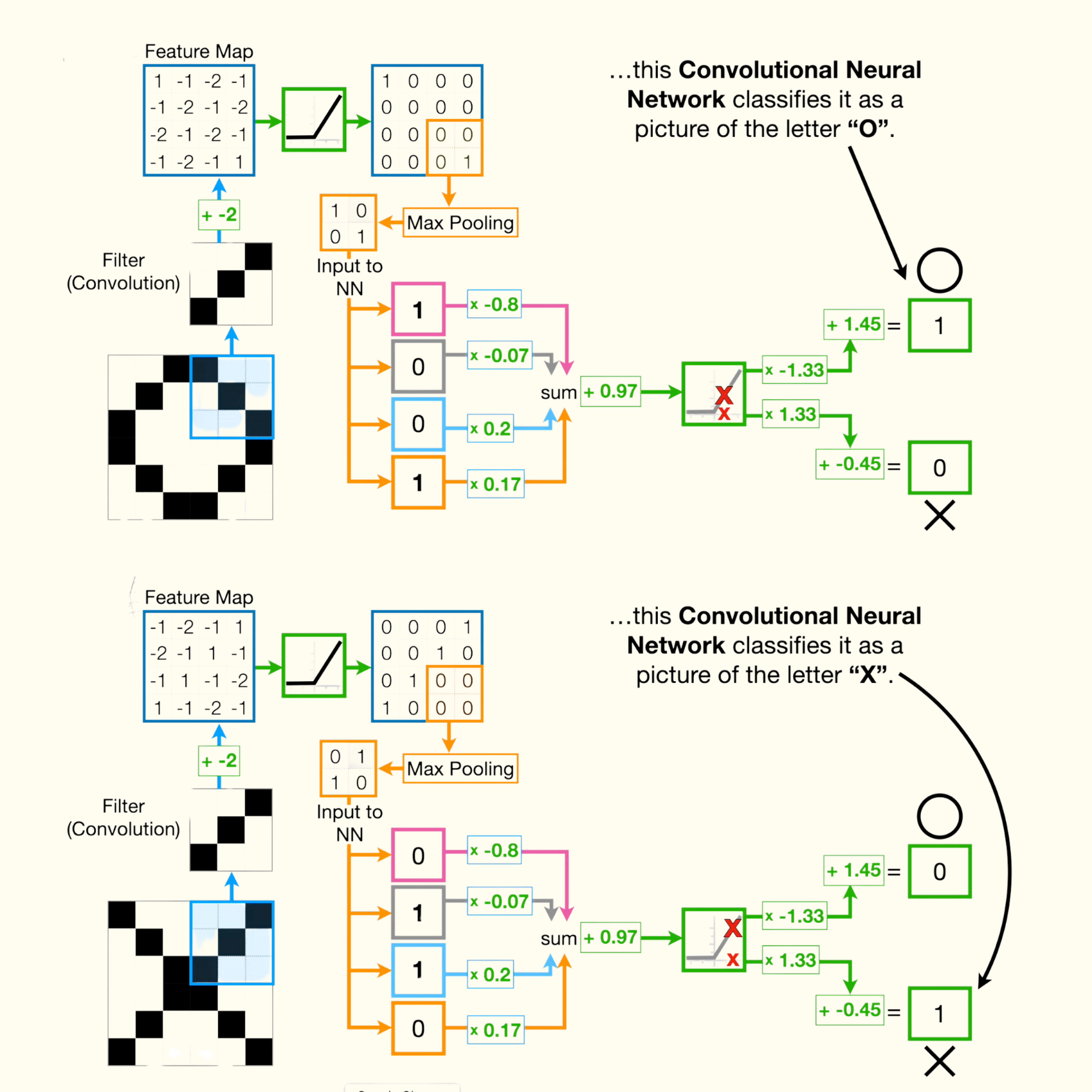
Components of CNN
Filter (aka kernel)
- In CNN, filter is just a smaller square that is commonly 3 pixels by 3 pixels, and the intensity of each pixels is determined by backpropagation.
- Before training a CNN, we start with random pixel values, and after training with backpropagation, we end up with something more useful.
- We have to compute the dot product (multiply and add each pixels) between the input and the filter. We can say that the filter is convolved with the input and that is what gives Convolution Neural Network its name.
- What it is: A small matrix (e.g., 3×3, 5×5) of trainable weights.
- Purpose: Detects patterns (edges, textures) in input images.
- How it works:
- Slides over the input image (stride=1 by default).
- Computes the dot product between filter weights and local pixel values.
- Training: Starts with random values → optimized via backpropagation.
Bias Term
- What it is: A single trainable value added to each filter’s output.
- Purpose: Adjusts the feature map’s baseline activation.
Feature Map
- What it is: Output after applying a filter to the input.
- Key Idea: Highlights where the filter’s pattern (e.g., edges) appears in the image.
- Example: A filter for "diagonal edges" activates on diagonal lines.
ReLU Activation
- Function: ReLU(x) = max(0, x)
- Purpose:
- Removes negative values (sets them to 0).
- Introduces nonlinearity, enabling complex feature learning.
Max Pooling
- What it does: Downsamples the feature map to reduce size/computation.
- How it works:
- Divides the feature map into windows (e.g., 2×2).
- Keeps only the maximum value in each window.
- Why?: Preserves important features while reducing spatial dimensions.
Flattening
- What it does: Converts the 2D feature maps into a 1D vector.
- Purpose: Prepares data for the final classification layer.
Fully Connected (FC) Layer
- What it is: A traditional neural network layer.
- Purpose: Classifies features into labels (e.g., "cat" or "dog").
- How it works:
- Takes flattened input.
- Applies weights and biases → outputs class probabilities via softmax.
Batch Normalization (BN) in CNNs
-
The Problem BatchNorm Solves
- In deep networks like CNNs:
- Activations (layer outputs) can become poorly scaled (e.g., too large/small).
- Unstable gradients make training slow or stuck.
- Example: If inputs to a layer (y = Wx) have varying scales, weights (W) must constantly adjust, slowing convergence.
- In deep networks like CNNs:
-
BatchNorm’s Core Idea
- Force each layer’s inputs to be zero-mean and unit-variance (per channel/dimension) for every batch during training.
- Normalize first, then scale/shift back (to preserve representational power).
-
How It Works (Step-by-Step)
- (1) For a Batch of Activations
- Let x be a batch of activations (shape: N × C × H × W for CNNs, where C = channels).
- For each channel c in C:
- (2) Compute Batch Statistics
- Mean (center the data):
- Variance (measure spread):
- (Tiny ε avoids division by zero.)
- Mean (center the data):
- (3) Normalize
- Center and scale each activation:
- (Now x̂ has mean=0, variance=1 per channel.)
- (4) Scale and Shift (Learnable Parameters)
- Introduce γ (scale) and β (shift) per channel to retain flexibility:
-
- γ and β are learned during training.
- If zero-mean/unit-variance hurts performance, the network can "undo" normalization by setting γ=σ, β=μ.
- During Testing
- Use population estimates of μ and σ² (averaged from training batches).
- BN becomes a fixed linear transformation:


