Lesson 2.3: Object Detection
Conventional Object Detection
- A fixed-size detection window slides across the image at multiple scales and aspect ratios.
- At each position, a classifier (e.g., SVM, CNN) checks if an object is present.
- Such as Haar, SIFT, HOG etc.
- DPM (Deformable Parts Model) models, Employed a sliding window approach to predict bounding boxes with higher scores.
- This kind of method was extremely time-consuming, and the accuracy was not very high.
Reasons for High Computational Cost:
- Number of Scales
- Objects appear at different sizes, requiring the window to resize and scan repeatedly.
- Example: A single image may need 10+ scale checks → more computations.
- Number of Aspect Ratios
- Objects vary in shape (wide cars, tall pedestrians).
- Checking multiple aspect ratios (e.g., 1:1, 2:3, 3:2) increases processing time.
- Sliding Across Width & Height
- The window moves pixel-by-pixel (or with a stride), leading to thousands of overlapping patches.
- Example: A 1000×1000px image with stride=16 → 3,900+ positions per scale!
Two Obvious Ways to Improve Sliding Window Approach
-
Speed Up the Deep Network Computation (Faster Processing per Window)
- Problem: Running a CNN on every sliding window is slow.
- Solution: Optimize the CNN for speed while maintaining accuracy.
- Use lighter architectures (e.g., MobileNet, SqueezeNet) for the sliding window classifier.
- Apply network pruning or quantization to reduce computation.
- Limitation: Even with a fast CNN, processing thousands of windows is inefficient.
-
Reduce the Number of Proposals (Pass Only Relevant Windows to CNN)
- Problem: Most sliding windows contain just background (no objects).
- Solution: Use a cheap pre-filtering method to eliminate useless windows before CNN processing.
- Traditional method: Selective Search (R-CNN) generates fewer but higher-quality proposals.
- Modern method: Region Proposal Network (RPN in Faster R-CNN) predicts likely object regions.
- Benefit: Instead of thousands of windows, only ~200-2000 proposals are passed to CNN → Major speedup!
Deep Learning Models for Object Detection
R-CNN(Regions with Convolutional Neural Network)
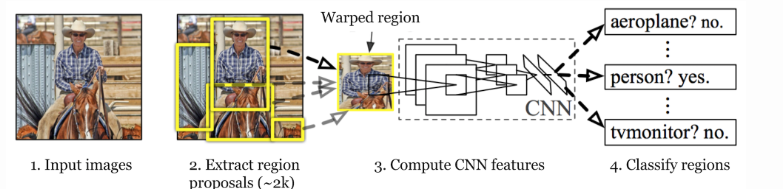
In R-CNN (Region-based CNN), the object detection pipeline is broken into three key steps to improve efficiency over the sliding window approach:
- Region Proposal Generation (Category-Independent)
- Goal: Generate ~2000 regions ("proposals") that might contain objects (without knowing what they are yet).
- Method: Uses Selective Search (a fast, heuristic-based algorithm) to:
- Merge similar pixels → forms potential object regions.
- Prioritizes regions with uniform texture/color (likely objects).
- Why? Avoids brute-force sliding windows by focusing only on "promising" areas.
- Feature Extraction (CNN)
- Each proposed region is warped to a fixed size and fed into a CNN (e.g., AlexNet) to extract features.
- Key Difference from Sliding Window:
- Processes ~2000 regions instead of millions of sliding windows.
- Classification (SVM) & Bounding Box Refinement
- Classification: An SVM assigns a class label (e.g., "car," "dog") to each region.
- Bounding Box Regression: Adjusts proposal coordinates for tighter object fits.