Lesson 2.2: Computer Vision Tasks
Computer vision is a field of artificial intelligence (AI) that enables machines to interpret and understand visual information from the world, such as images and videos. It involves various tasks that mimic human visual perception. Here are some key computer vision tasks:

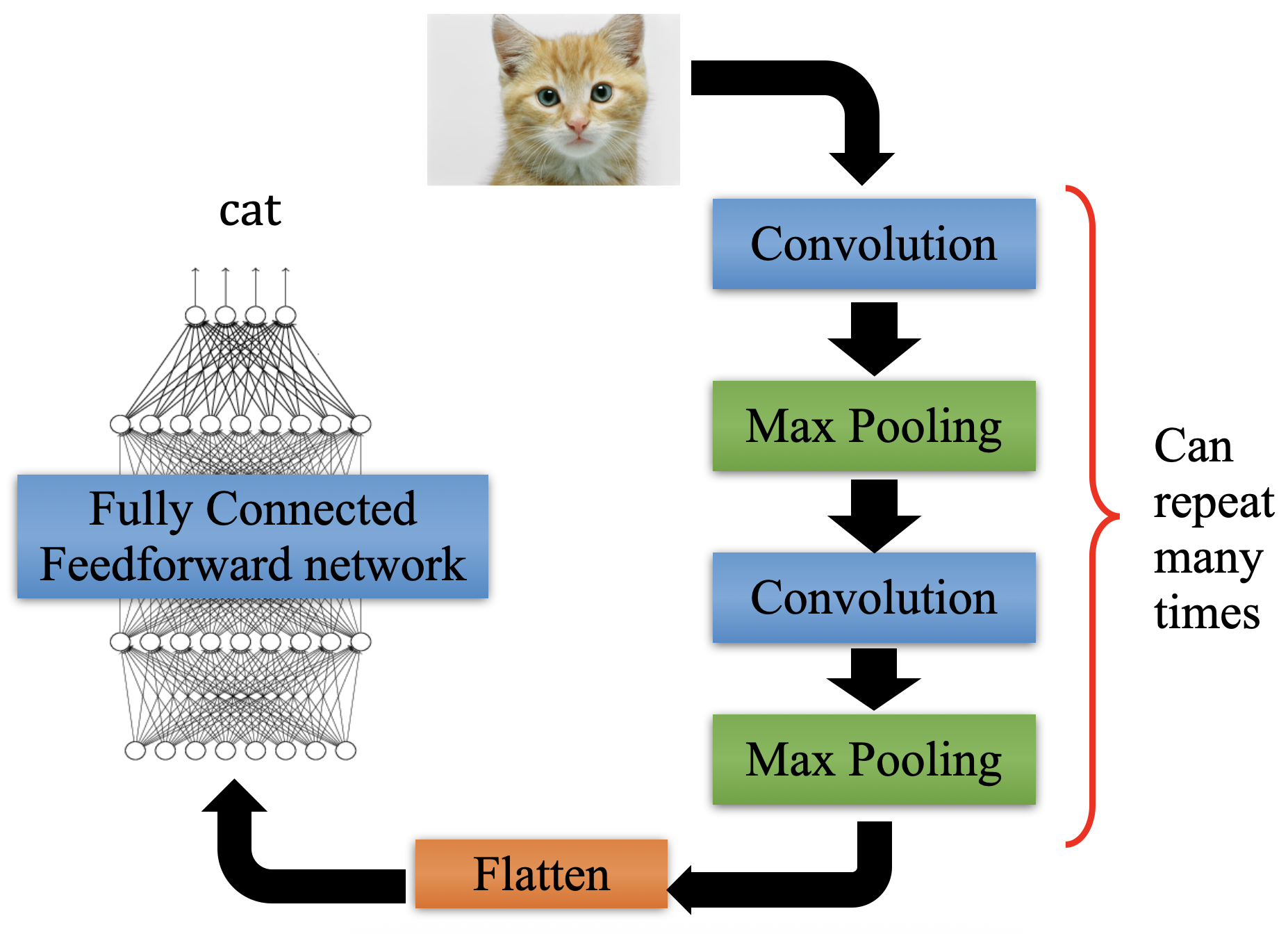
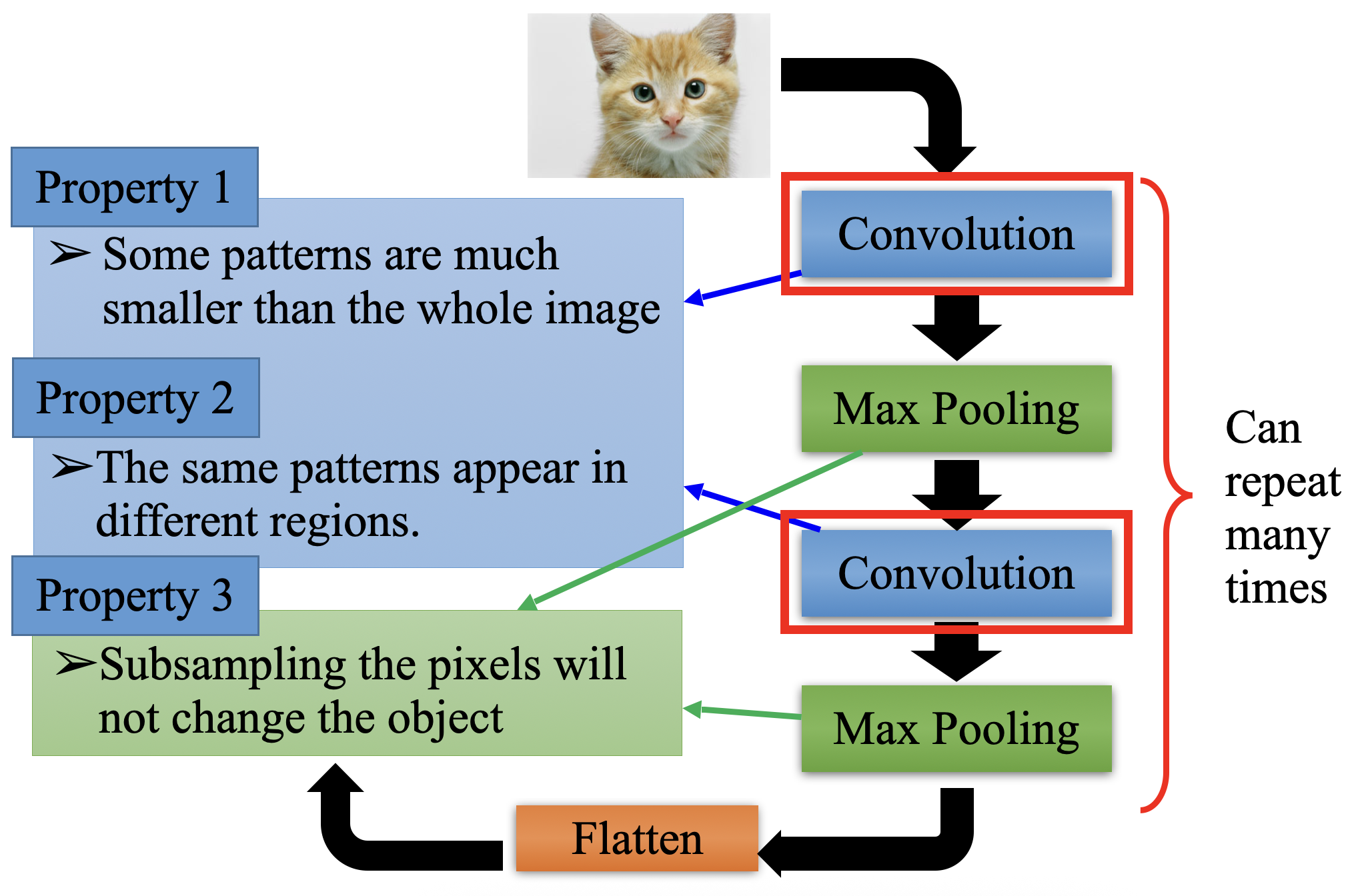
1. Image Classification
- Goal: Assign a label to an entire image (e.g., "cat," "dog," "car").
- Example: Identifying whether an image contains a cat or a dog.
- Models: CNN (Convolutional Neural Networks), ResNet, ViT (Vision Transformer).
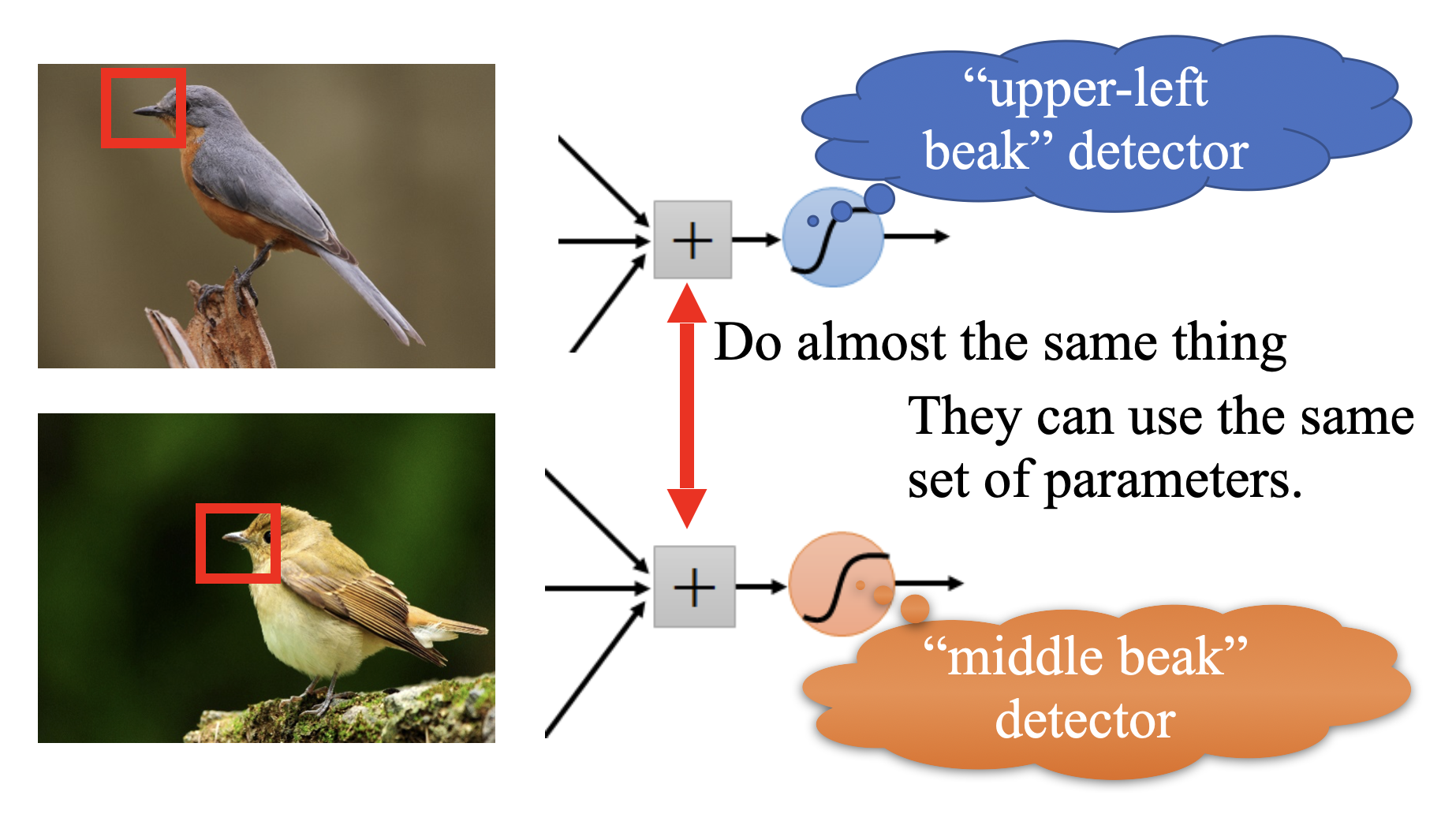
2. Object Detection
- Goal: Locate and classify multiple objects within an image using bounding boxes.
- Example: Detecting pedestrians, cars, and traffic signs in a self-driving car system.
- Models: YOLO (You Only Look Once), Faster R-CNN, SSD (Single Shot MultiBox Detector).
3. Semantic Segmentation
- Goal: Assign a class label to each pixel in an image (dense prediction).
- Example: Medical image analysis (identifying tumors in MRI scans).
- Models: U-Net, FCN (Fully Convolutional Network), DeepLab.
4. Instance Segmentation
- Goal: Detect and segment individual object instances (combines object detection + semantic segmentation).
- Example: Differentiating between multiple cars in an image.
- Models: Mask R-CNN, SOLO (Segmenting Objects by Locations).
5. Object Tracking
- Goal: Follow a specific object's movement across video frames over time.
- Example: Tracking a player in a sports video.
- Methods: SORT (Simple Online and Realtime Tracking), DeepSORT, Kalman Filters.
6. Pose Estimation (Keypoint Detection)
- Goal: Detect human or animal body poses by identifying key joints (e.g., elbows, knees).
- Example: Fitness apps analyzing workout form.
- Models: OpenPose, HRNet (High-Resolution Network).
7. Depth Estimation
- Goal: Predict the distance (depth) of objects from the camera.
- Example: Autonomous robots navigating environments.
- Methods: Stereo vision, Monocular depth estimation (MiDaS, DORN).
8. Image Generation & Synthesis
- Goal: Create new images using AI (e.g., GANs, Diffusion Models).
- Example: Generating realistic faces with StyleGAN.
- Models: GANs (Generative Adversarial Networks), Stable Diffusion.
9. Optical Character Recognition (OCR)
- Goal: Extract text from images or scanned documents.
- Example: Digitizing handwritten notes or license plate recognition.
- Tools: Tesseract, EasyOCR, PaddleOCR.
10. Face Recognition
- Goal: Identify or verify a person’s identity using facial features.
- Example: Unlocking smartphones with Face ID.
- Models: FaceNet, ArcFace, DeepFace.
11. Action Recognition (Video Analysis)
- Goal: Classify human actions in videos (e.g., running, dancing).
- Example: Surveillance systems detecting suspicious activities.
- Models: 3D CNNs, Two-Stream Networks, SlowFast.
12. Image Super-Resolution
- Goal: Enhance low-resolution images to higher resolution.
- Example: Upscaling old photos.
- Models: SRGAN (Super-Resolution GAN), ESRGAN.
13. Image Captioning
- Goal: Generate a textual description of an image.
- Example: Helping visually impaired users understand images.
- Models: CNN + RNN (e.g., Show and Tell), Transformers (e.g., BLIP).
14. Anomaly Detection
- Goal: Identify unusual patterns or defects in images.
- Example: Detecting cracks in industrial products.
- Methods: Autoencoders, GAN-based anomaly detection.
15. Visual Question Answering (VQA)
- Goal: Answer questions about an image.
- Example: AI answering "What color is the car?" from an image.
- Models: LSTM + CNN, Vision-Language Transformers (e.g., BLIP-2)