Lesson 3.7: Transformers
Word Embeddings
Coverting input phrase to numbers. (Eg., Let's go -> "Numbers")
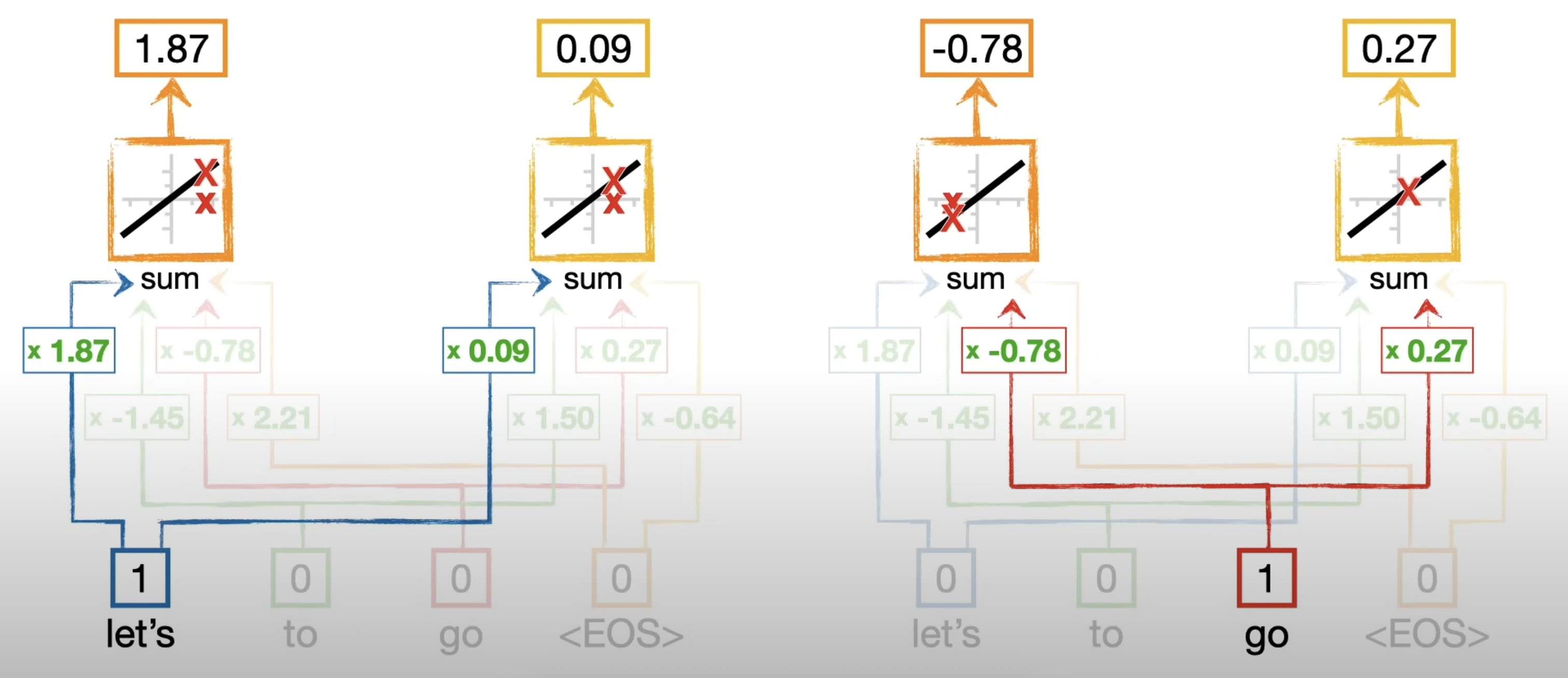
- The weights in the network for
let'sis exactly same for thelet'sin the network forgo.
Positional Encoding
It is a technique that transformers use to keep track of word order.
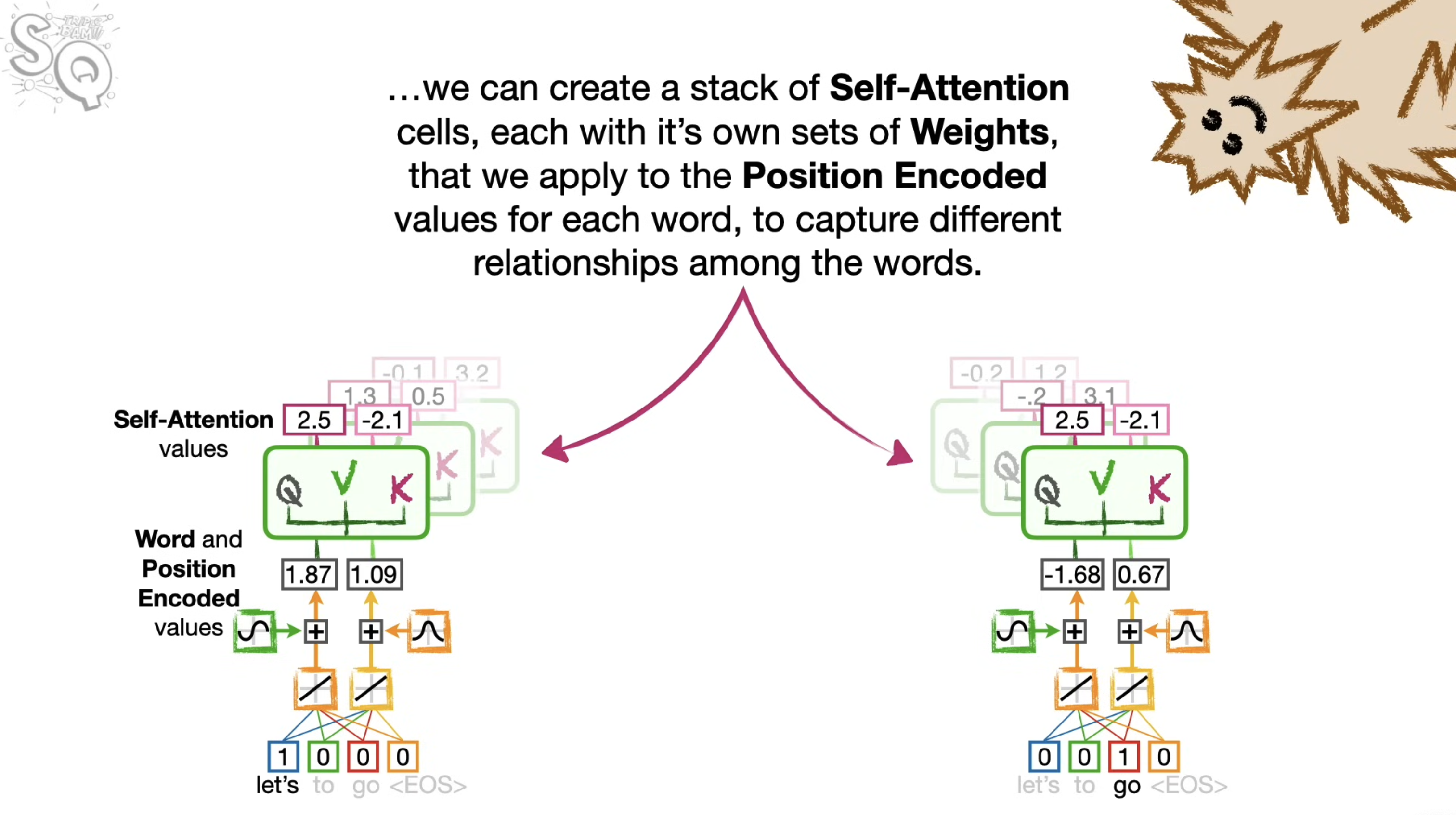
Self attention
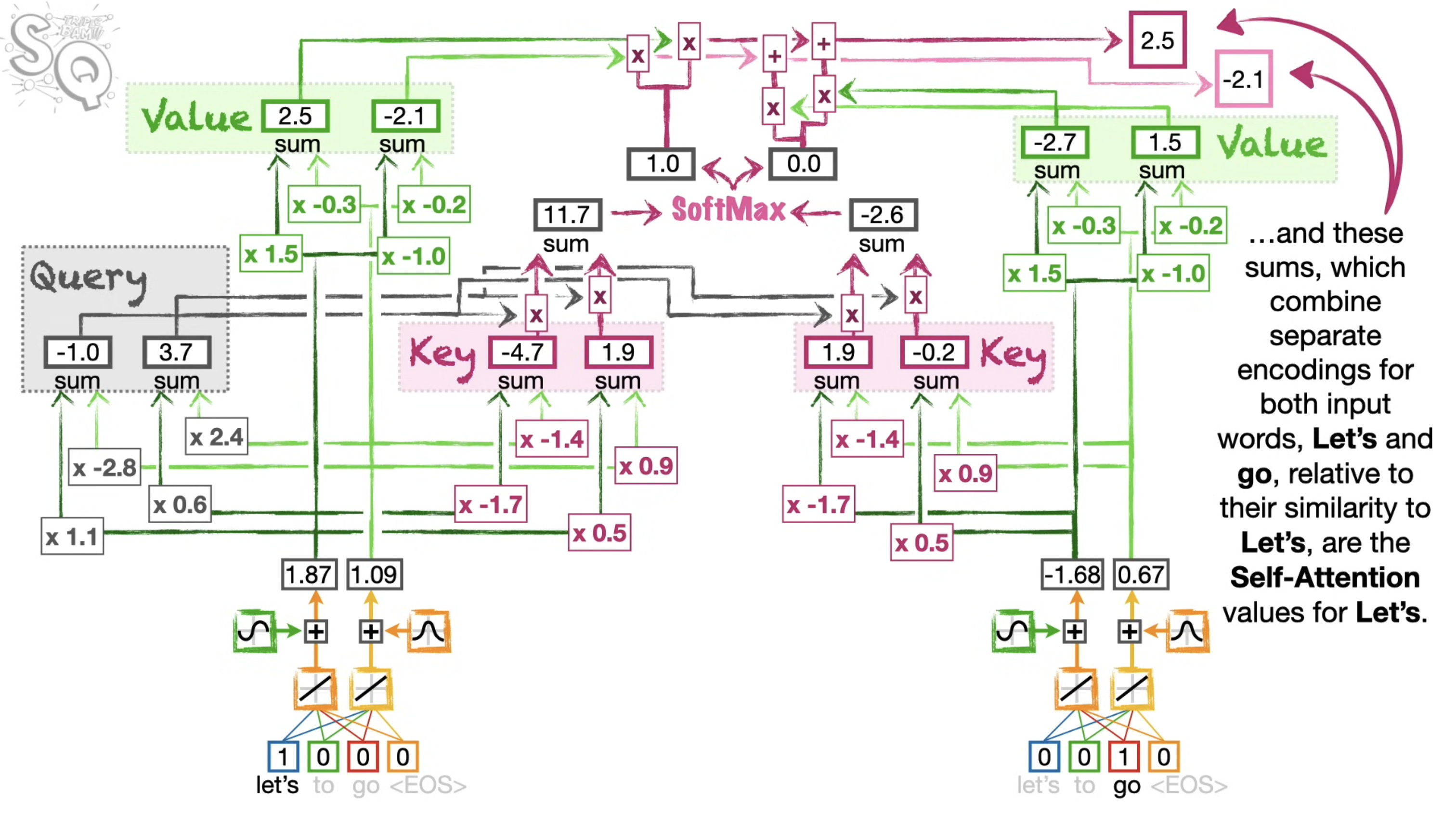
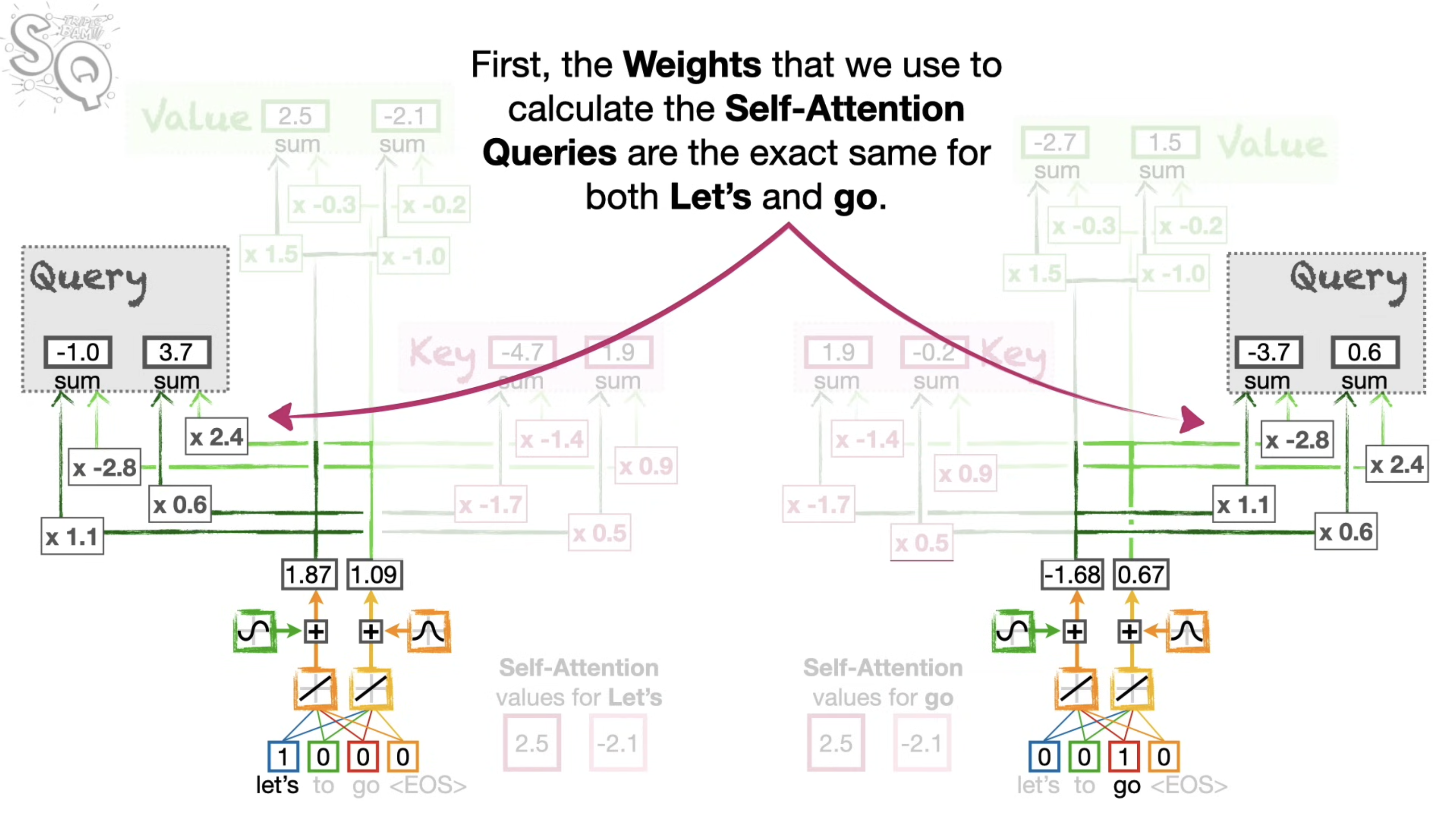
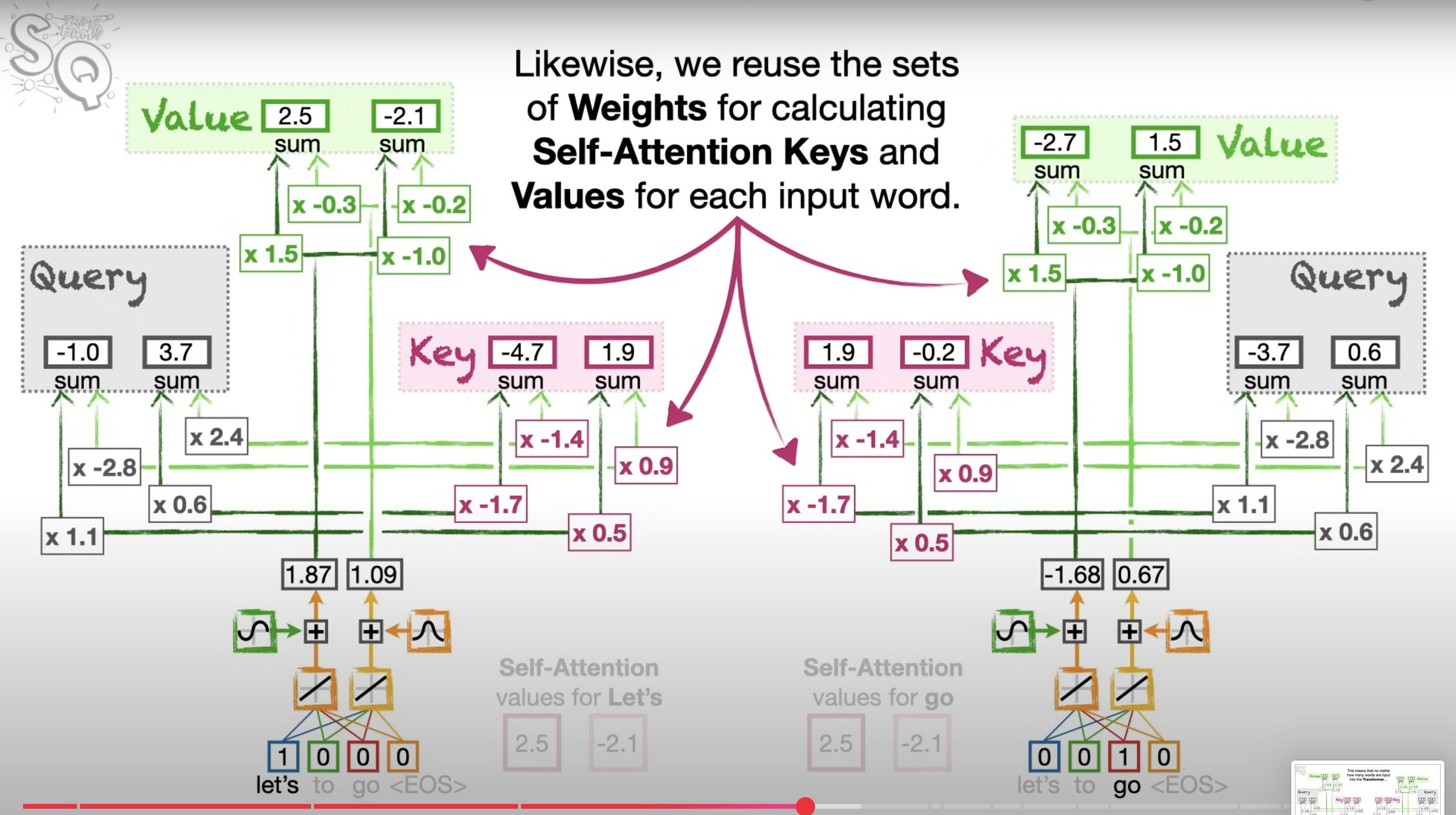
- We can calucluate the Query, Key, and Values for each word at the same time. In other word, we dont have to calculate Q,K,V for the first word, before moving on the secind word. And because we can do all the computations at the same time, Transformers can take the advantage of parallel computing and run fast.
Multi-Head Attention
Residual Connections
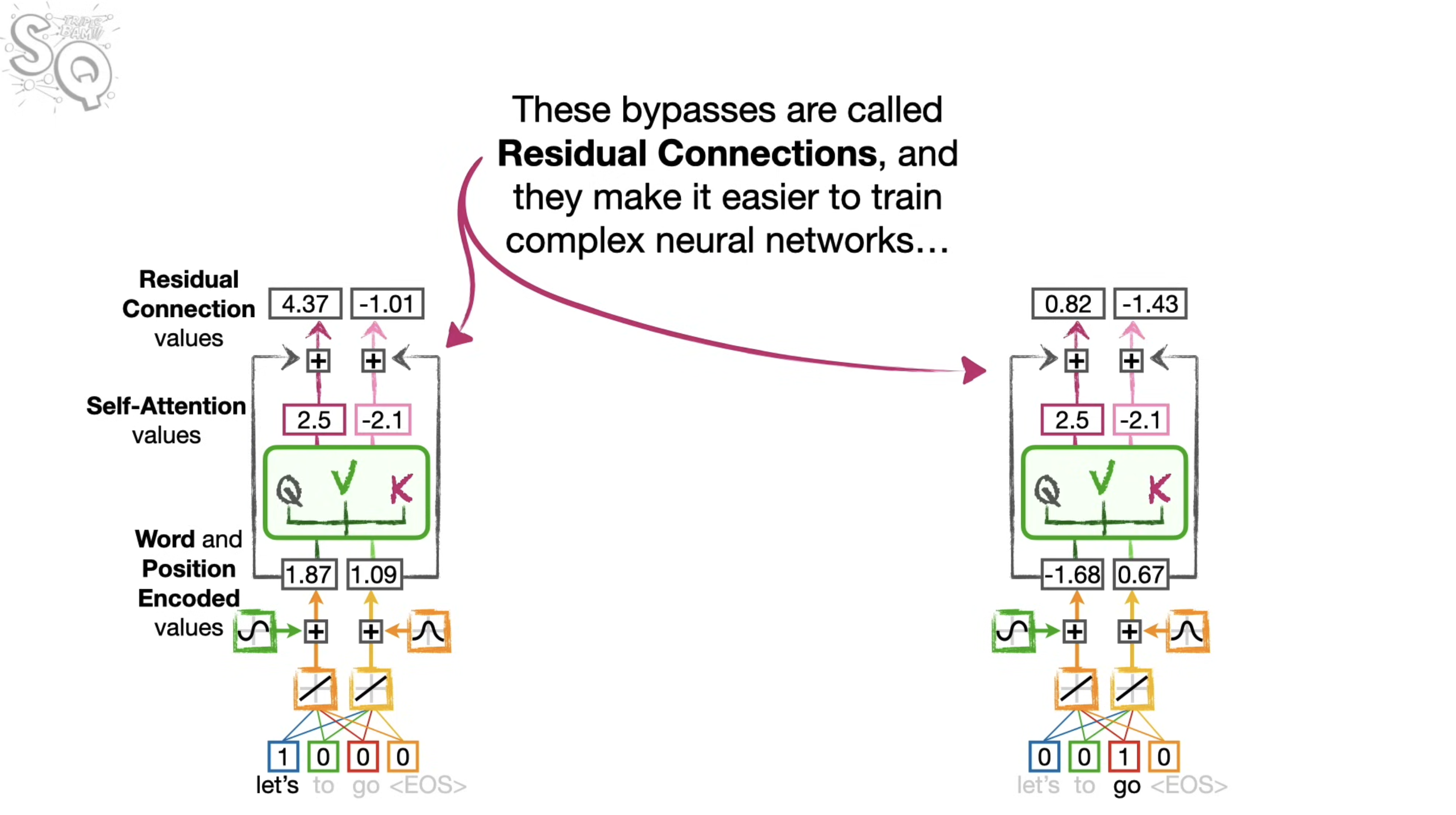 These bypasses are called residual connections, and they make it easier to train complex neural networks, by allowing the self-attention layers to establish relationship among the input words without having to preserve the word embedding and positional encoding information.
These bypasses are called residual connections, and they make it easier to train complex neural networks, by allowing the self-attention layers to establish relationship among the input words without having to preserve the word embedding and positional encoding information.
Encoding part of the Transformer
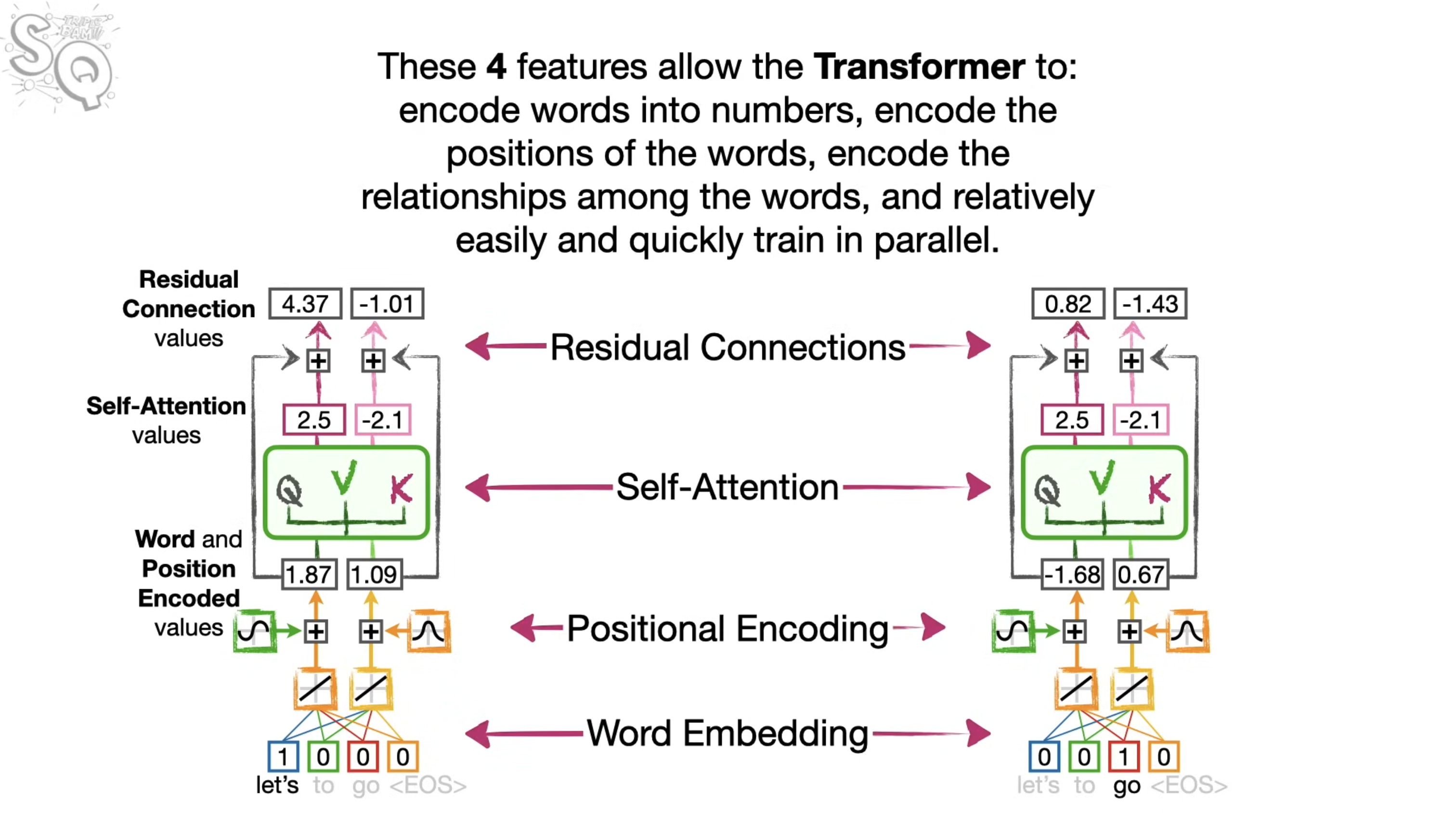
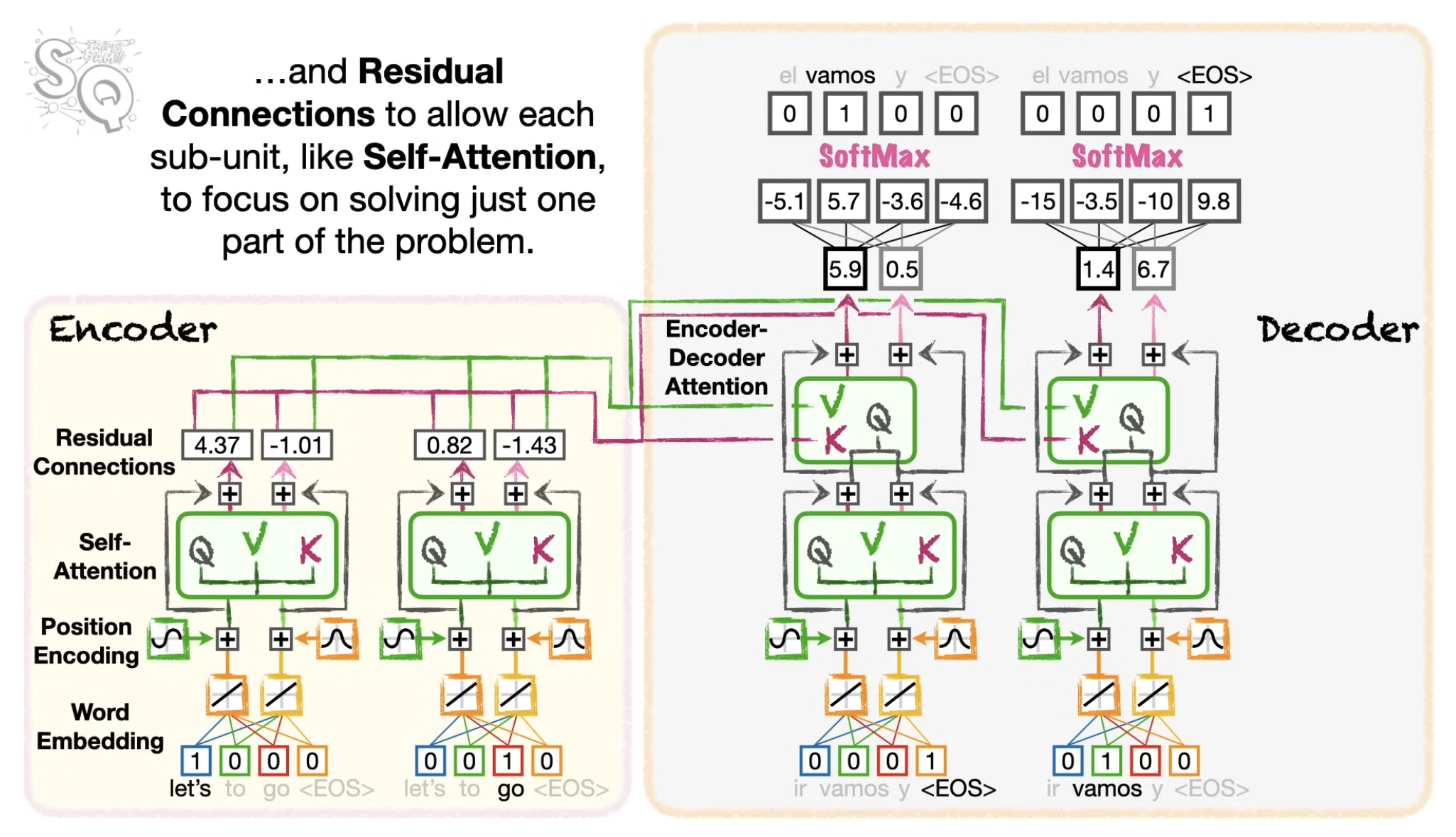
- So far, we have talked about how self-attention help the transformers to keep track of how words are related within a sentence, however in this example we are translating a sentence, we also need to keep track of the input sentence and the output sentence.
Example :
- Don't eat the delicious looking and smelling pizza.
- Eat the delicious looking and smelling pizza. These two sentence have totally opposite meanings, if the translation focus on other part of the sentence and omits the don't. So it's super important for the decoder to keep track of the words. So the main idea of the encoder-decoder attention is to allow the Decoder to keep track of the significant words in the input.
The Transformer Architecture
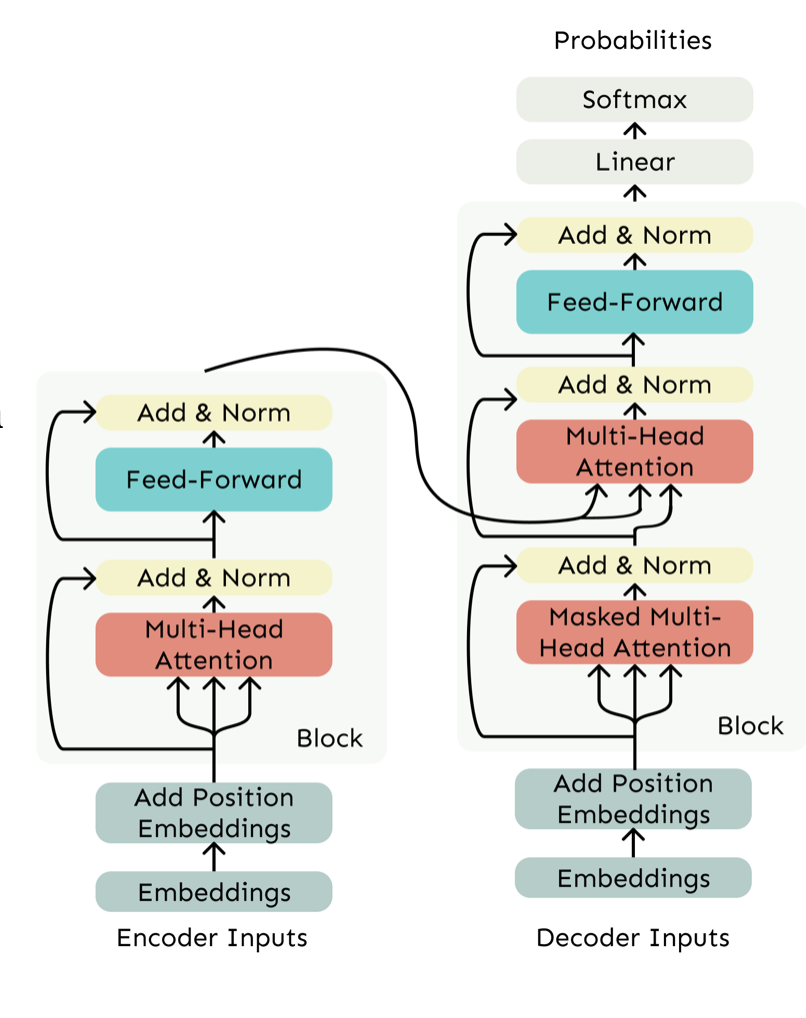
The Transformer Architecture Explained in Sentences The Transformer architecture is a neural network model introduced in the 2017 paper "Attention Is All You Need", designed to process sequential data like text without using recurrent connections. Instead of relying on the sequential processing of RNNs or LSTMs, Transformers use self-attention mechanisms to capture relationships between all words in a sentence simultaneously, enabling parallel computation and better handling of long-range dependencies.
The architecture consists of two main components: the Encoder and the Decoder, which can be used separately or together depending on the task.
1. Encoder (Bidirectional Context Processing)
The encoder processes input sequences (e.g., a sentence in machine translation) to generate contextualized representations for each word. It consists of multiple identical layers, each containing:
- Self-Attention: Computes attention weights between all words in the input, allowing each word to focus on relevant parts of the sentence.
- Feed-Forward Network (FFN): A small neural network applied independently to each position, introducing nonlinearity.
- Residual Connections & Layer Normalization: Help stabilize training by allowing gradients to flow directly through the network. Since the encoder processes the entire input at once (unlike RNNs), it uses no masking, meaning each word can attend to all other words in the sentence.
2. Decoder (Autoregressive Generation)
The decoder generates output sequences (e.g., a translated sentence) one word at a time, using:
- Masked Self-Attention: Ensures that when predicting a word at position i, the model only sees words before i (no future peeking).
- Cross-Attention: Connects the decoder to the encoder, allowing it to focus on relevant parts of the input sequence when generating each output word.
- Feed-Forward Network & Residual Connections: Similar to the encoder, but applied in an autoregressive manner. Unlike the encoder, the decoder uses masking to prevent information leakage from future tokens, making it suitable for tasks like language modeling and machine translation.
Key Innovations
Multi-Head Attention: Instead of a single attention mechanism, Transformers use multiple "heads" to focus on different aspects of the input (e.g., syntax, semantics).
- Positional Encodings: Since self-attention is order-agnostic, positional information is added to word embeddings to preserve sequence order.
- Scaled Dot-Product Attention: The attention scores are scaled by the square root of the key dimension to prevent large values from dominating softmax.
- Layer Normalization & Residual Connections: Help train deep networks by reducing vanishing gradients.
Applications
- Encoder-Only Models (e.g., BERT): Used for tasks like text classification and named entity recognition.
- Decoder-Only Models (e.g., GPT): Used for autoregressive generation (e.g., text completion).
- Encoder-Decoder Models (e.g., T5, BART): Used for sequence-to-sequence tasks like translation and summarization.
Why Transformers Are Better Than RNNs
- Parallelization: Unlike RNNs, which process words sequentially, Transformers compute attention in parallel, making them faster on GPUs.
- Long-Range Dependencies: Self-attention directly connects distant words, avoiding the vanishing gradient problem in RNNs.
- Scalability: Can handle much longer sequences than RNNs when combined with efficient attention variants (e.g., sparse attention).
In summary, the Transformer replaces recurrence with self-attention, positional encodings, and feed-forward networks, enabling faster, more accurate, and more parallelizable sequence modeling. It has become the foundation for modern NLP models like GPT, BERT, and T5.
Drawbacks and Variants of Transformers
What would we like to fix about the Transformer?
Quadratic compute in self-attention:
- Computing all pairs of interactions means our computation grows quadratically with the sequence length!
- For recurrent models, it only grew linearly!
Position representations:
- Are simple absolute indices the best we can do to represent position?
- Relative Position Representations
- Structural Position Representations
- Rotary Embeddings