Lesson 3.4: Gated Recurrent Units (GRU)
GRUs are a streamlined variant of LSTMs designed to capture long-range dependencies while being computationally lighter. They achieve this through two gating mechanisms (no separate cell state) that regulate information flow.
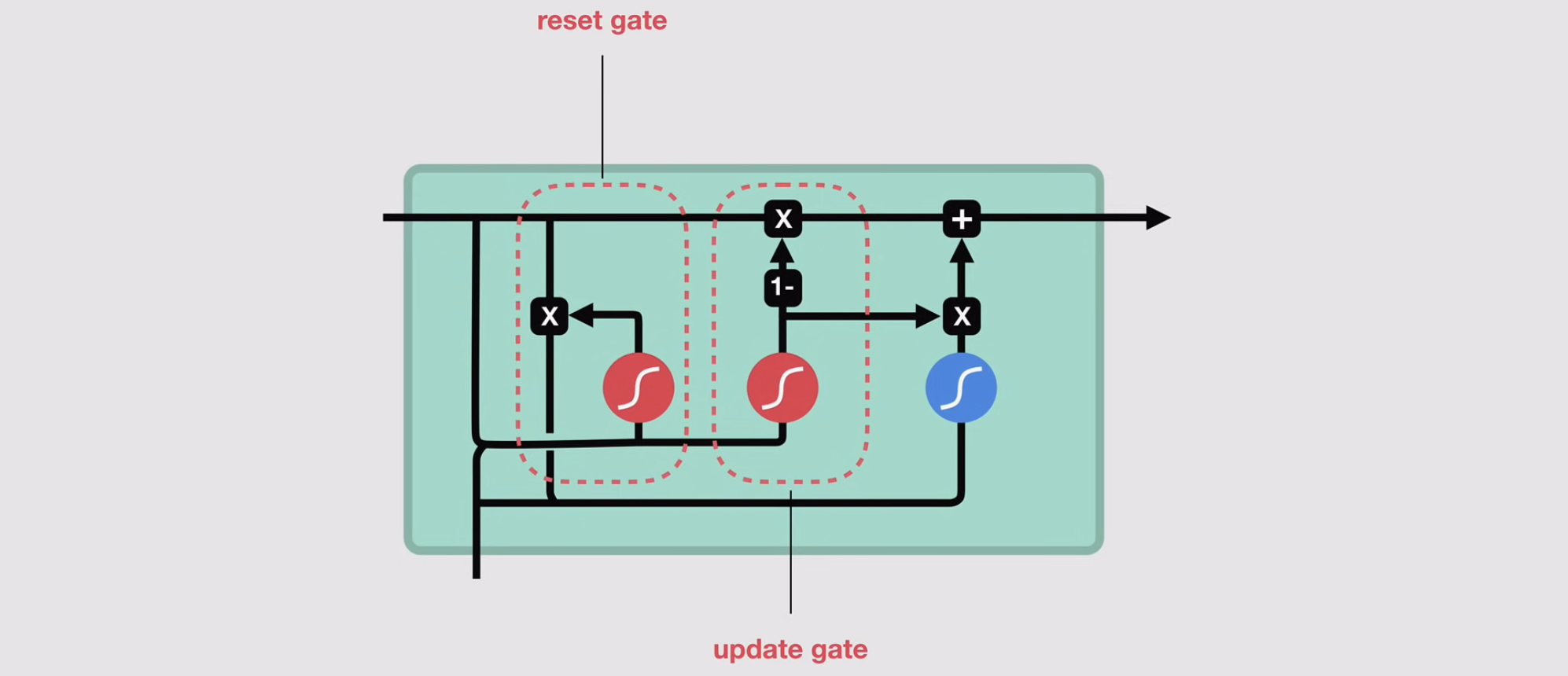
- Update Gate ()
- Role: Decides how much of the past hidden state to retain vs. how much to update with new information.
- Equation :
- : Sigmoid (outputs values between 0 and 1).
- Interpretation:
- : Keep most of the past state (like LSTM’s forget gate).
- : Focus on new input (like LSTM’s input gate).
-
Reset Gate ()
- Role: Determines how much of the past hidden state to ignore when computing the new candidate state.
- Equation:
- Interpretation:
- : "Reset" (ignore past state, focus only on current input).
- : Integrate past and current info.
-
Candidate Hidden State ( )
- Role: Proposed new state based on the reset gate and current input.
- Equation:
- Key:
- ⊙: Element-wise multiplication.
- If the candidate ignores (only uses ).
- Final Hidden State ( )
- Role: Blends the past state and candidate using the update gate.
- Equation:
- Interpretation:
- Replace with
- Keep unchanged.
Why GRUs Solve Vanishing Gradients
- Additive Updates: Like LSTMs, GRUs use summation (not multiplication) to combine states, preserving gradients:
- Gradient Paths:
- The reset gate can learn to ignore irrelevant history.
- The update gate can learn to preserve critical long-term info.
GRU vs. LSTM
| Feature | GRU | LSTM |
|---|---|---|
| Gates | 2 (update, reset) | 3 (forget, input, output) |
| Cell State | None (hidden state only) | Explicit cell state () |
| Complexity | Fewer parameters (faster) | More expressive (slower) |
| Use Cases | Short-medium sequences | Very long sequences |
- GRUs simplify LSTMs by combining forget/input gates into an update gate and removing the cell state.
- Reset Gate: Filters irrelevant past info.
- Update Gate: Balances old/new memory.
- Advantage: Faster to train than LSTMs while often achieving comparable performance.